Are you preparing for a SQL developer interview?
Then you’ve come to the right place.
This guide will help you improve your SQL skills, regain your confidence, and be ready for work!
In this collection of SQL Common Interview Questions and Answers, you’ll find a collection of authentic interview questions from companies like Google, Oracle, Amazon, and Microsoft. Each question is accompanied by a perfect inline answer, saving you time in interview preparation.
It also includes practice questions to help you understand the basic concepts of SQL.
We have divided this article into the following sections:
- SQL Interview Questions
- PostgreSQL Interview Questions
What are the common interview questions in SQL?
What is a database?
A database is an organized collection of data that is stored and retrieved digitally from a remote or local computer system. Databases can be large and complex, and such databases are developed using fixed design and modeling methods.
What is a database management system?
SQL Interview Question Analysis: DBMS stands for Database Management System. DBMS is the system software responsible for creating, retrieving, updating, and managing databases. It ensures that our data is consistent, organized, and easily accessible by acting as an interface between the database and its end users or application software.
What is a relational database? How is it different from a DBMS?
RDBMS stands for Relational Database Management System. The key difference here compared to a DBMS is that an RDBMS stores data in the form of a collection of tables, and relationships can be defined between the common fields of those tables. Most modern database management systems, such as MySQL, Microsoft SQL Server, Oracle, IBM DB2, and Amazon Redshift, are based on RDBMS.
What is SQL?
SQL stands for Structured Query Language. It is the standard language for relational database management systems. It is especially useful when working with organized data that consists of entities (variables) and relationships between different data entities.
What is the difference between SQL and MySQL?
SQL is a standard language for retrieving and manipulating structured databases. Instead, MySQL is a relational database management system, similar to SQL Server, Oracle, or IBM DB2, for managing SQL databases.
What are tables and fields?
A table is an organized collection of data stored in the form of rows and columns. Columns can be categorized as vertical, and rows can be categorized as horizontal. The columns in a table are called fields, while the rows can be called records.
What are the constraints in SQL?
Constraints are used to specify rules about the data in a table. It can be applied to single or multiple fields in a SQL table during table creation or after creation using the ALTER TABLE command. The constraints are:
- NOT NULL—Restricts the insertion of NULL values into columns.
- CHECK—Verify that all values in the field meet the criteria.
- DEFAULT—If no value is specified for the field, a default value is automatically assigned.
- UNIQUE – Ensures that a unique value is inserted into the field.
- INDEX – Indexes a field, providing faster record retrieval.
- PRIMARY KEY—UNIQUELY IDENTIFIES EACH RECORD IN THE TABLE.
- FOREIGN KEY—ENSURES THE REFERENTIAL INTEGRITY OF A RECORD IN ANOTHER TABLE.
What is a primary key?
THE PRIMARY KEY CONSTRAINT UNIQUELY IDENTIFIES EACH ROW IN THE TABLE. It must contain a UNIQUE value and have an implicit NOT NULL constraint.
Tables in SQL are strictly limited to a single primary key, which consists of one or more fields (columns).
CREATE TABLE Students ( /* Create table with a single field as primary key */
ID INT NOT NULL
Name VARCHAR(255)
PRIMARY KEY (ID)
);
CREATE TABLE Students ( /* Create table with multiple fields as primary key */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL,
CONSTRAINT PK_Student
PRIMARY KEY (ID, FirstName)
);
ALTER TABLE Students /* Set a column as primary key */
ADD PRIMARY KEY (ID);
ALTER TABLE Students /* Set multiple columns as primary key */
ADD CONSTRAINT PK_Student /*Naming a Primary Key*/
PRIMARY KEY (ID, FirstName);Write an SQL statement to add the primary key ‘t_id’ to the teachers table.
Write a SQL statement that adds the primary key constraint ‘pk_a’ to the table ‘table_a’ and the field ‘col_b’ col_c.
WHAT IS A UNIQUE CONSTRAINT?
The UNIQUE constraint ensures that all values in the column are different. This provides uniqueness to the columns and helps to uniquely identify each row. Unlike primary keys, each table can define multiple unique constraints. UNIQUE’S CODE SYNTAX IS VERY SIMILAR TO PRIMARY KEY’S CODE SYNTAX AND CAN BE USED INTERCHANGEABLY.
CREATE TABLE Students ( /* Create table with a single field as unique */
ID INT NOT NULL UNIQUE
Name VARCHAR(255)
);
CREATE TABLE Students ( /* Create table with multiple fields as unique */
ID INT NOT NULL
LastName VARCHAR(255)
FirstName VARCHAR(255) NOT NULL
CONSTRAINT PK_Student
UNIQUE (ID, FirstName)
);
ALTER TABLE Students /* Set a column as unique */
ADD UNIQUE (ID);
ALTER TABLE Students /* Set multiple columns as unique */
ADD CONSTRAINT PK_Student /* Naming a unique constraint */
UNIQUE (ID, FirstName);What is a foreign key?
A FOREIGN KEY CONSISTS OF A SINGLE FIELD OR COLLECTION OF FIELDS IN A TABLE THAT ESSENTIALLY REFERS TO THE PRIMARY KEY IN ANOTHER TABLE. Foreign key constraints ensure the referential integrity of the relationship between two tables.
Tables with foreign key constraints are marked as child tables, and tables with candidate keys are marked as referenced or parent.
CREATE TABLE Students ( /* Create table with foreign key - Way 1 */
ID INT NOT NULL
Name VARCHAR(255)
LibraryID INT
PRIMARY KEY (ID)
FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
CREATE TABLE Students ( /* Create table with foreign key - Way 2 */
ID INT NOT NULL PRIMARY KEY
Name VARCHAR(255)
LibraryID INT FOREIGN KEY (Library_ID) REFERENCES Library(LibraryID)
);
ALTER TABLE Students /* Add a new foreign key */
ADD FOREIGN KEY (LibraryID)
REFERENCES Library (LibraryID);What type of integrity constraints does foreign keys ensure?
Write a SQL statement that adds a FOREIGN KEY ‘col_fk’ referencing the ‘col_pk’ in the ‘table_x’ to the ‘table_y’.
SQL common interview questions: What is a join? List the different types of it.
The SQL Join clause is used to combine records (rows) from two or more tables in SQL Database based on related columns between two or more tables.
There are four different types of JOINs in SQL:
- (INNER) JOIN: Retrieves records that have matching values in the two tables involved in the join. This is a connection that is widely used for queries.
SELECT *
FROM Table_A
JOIN Table_B;
SELECT *
FROM Table_A
INNER JOIN Table_B;- LEFT (OUTER) JOIN: RETRIEVES ALL RECORDS/ROWS FROM THE LEFT AND MATCHING RECORDS/ROWS FROM THE TABLE ON THE RIGHT.
SELECT *
FROM Table_A A
LEFT JOIN Table_B B
ON A.col = B.col;- RIGHT (OUTER) JOIN: RETRIEVES ALL RECORDS/ROWS FROM THE RIGHT AND MATCHING RECORDS/ROWS FROM THE TABLE ON THE LEFT.
SELECT *
FROM Table_A A
RIGHT JOIN Table_B B
ON A.col = B.col;- FULL (OUTER) JOIN: RETRIEVES ALL RECORDS IN THE LEFT OR RIGHT TABLE WHERE THERE IS A MATCH.
SELECT *
FROM Table_A A
FULL JOIN Table_B B
ON A.col = B.col;What is self-connectivity?
A self-join is a case of a regular join, where one is connected to itself based on some relationship between its own column(s). Self-joins use INNER JOIN or LEFT JOIN clauses, and table aliases are used to assign different names to tables in a query.
SELECT A.emp_id AS "Emp_ID",A.emp_name AS "Employee",
B.emp_id AS "Sup_ID",B.emp_name AS "Supervisor"
FROM employee A, employee B
WHERE A.emp_sup = B.emp_id;What is a cross-connect?
A cross join can be defined as the Cartesian product of the two tables contained in the join. The joined table contains the same number of rows as the number of rows in the cross product of the number of rows in both tables. If you use a WHERE clause in a cross join, the query will work like an INNER JOIN.
SELECT stu.name, sub.subject
FROM students AS stu
CROSS JOIN subjects AS sub;Write SQL statements to CROSS JOIN ‘table_1’ and ‘table_2’ and get ‘col_1’ from table_2 from table_1 and ‘col_2’, respectively. Don’t use aliases.
Write SQL statements to perform SELF JOINS for ‘Table_X’ aliases ‘Table_1’ and ‘Table_2’ on columns ‘Col_1’ and ‘Col_2’, respectively.
What is an index? Explain the different types of it.
A database index is a data structure that quickly looks up data in one or more columns of a table. It increases the speed of operations to access data from database tables, but requires additional writes and memory to maintain the index data structure.
CREATE INDEX index_name /* Create Index */
ON table_name (column_1, column_2);
DROP INDEX index_name; /* Drop Index */Different types of indexes can be created for different purposes:
- Unique and non-unique indexes:
A unique index is an index that helps maintain data integrity by ensuring that no two rows of data in a table have the same key value. Once a unique index is defined for a table, uniqueness is enforced whenever a key is added or changed in the index.
CREATE UNIQUE INDEX myIndex
ON students (enroll_no);Non-unique indexes, on the other hand, are not used to enforce constraints on the tables associated with them. Conversely, non-unique indexes are only used to improve query performance by maintaining the sort order of frequently used data values.
- Clustered and non-clustered indexes:
A clustered index is an index in which the order of rows in a database corresponds to the order of rows in an index. This is why only one clustered index can exist in a given table, whereas multiple nonclustered indexes can exist in a table.
The only difference between clustered and non-clustered indexes is that the database manager attempts to save the data in the database in the same order in which the corresponding keys appear in the clustered index.
Clustered indexes can improve the performance of most query operations because they provide a linear access path to the data stored in the database.
Write a SQL statement to create a unique index “my_index” on the “my_table” for the fields “column_1” and “column_2”.
What is the difference between clustered and non-clustered indexes?
As mentioned above, the difference can be divided into three minor factors-
- Clustered indexes modify how records are stored in the database based on the index columns. A nonclustered index creates a separate entity in the table that references the original table.
- Clustered indexes are used to retrieve data from databases easily and quickly, whereas fetching records from non-clustered indexes is relatively slow.
- In SQL, a table can have one clustered index, while it can have multiple nonclustered indexes.
What is data integrity?
Data integrity is the assurance of the accuracy and consistency of data throughout its lifecycle and is a critical aspect of the design, implementation, and use of any system that stores, processes, or retrieves data. It also defines integrity constraints to enforce business rules on data when it is entered into an application or database.
What is an inquiry?
A query is a request for data or information from a database table or a combination of tables. A database query can be a selection query or an action query.
SELECT fname, lname /* select query */
FROM myDb.students
WHERE student_id = 1;UPDATE myDB.students /* action query */
SET fname = 'Captain', lname = 'America'
WHERE student_id = 1;SQL Collection of Common Interview Questions and Answers: What is a Subquery? What are its types?
A subquery is a query within another query, also known as a nested query or an internal query. Used to limit or enhance the data to be queried by the main query, thereby limiting or enhancing the output of the primary query, respectively. For example, here we get the contact information of students who are enrolled in a math subject:
SELECT name, email, mob, address
FROM myDb.contacts
WHERE roll_no IN (
SELECT roll_no
FROM myDb.students
WHERE subject = 'Maths');There are two types of subqueries – Correlated and Non-Correlated.
- A related subquery cannot be thought of as a standalone query, but it can refer to a list listed in the main query.
- An unrelated subquery can be thought of as a separate query, with the output of the subquery being replaced in the main query.
Write a SQL query to update the field ‘status’ in table ‘applications’ from 0 to 1.
Write a SQL query to select the field app_id in the table applications that has a app_id less than 1000.
Write a SQL query to get the field “app_name” from “apps”, where “apps.id” equals the “app_id” set above.
What is a SELECT statement?
The SELECT operator in SQL is used to select data from the database. The returned data is stored in a result table, called a result set.
SELECT * FROM myDB.students;What are the commonly used clauses for SELECT query in SQL?
Some common SQL clauses used in conjunction with SELECT queries are as follows:
- The WHERE clause in SQL is used to filter the necessary records based on specific criteria.
- The ORDER BY clause in SQL is used to sort records in ascending order (ASC) or descending order (DESC) based on certain fields.
SELECT *
FROM myDB.students
WHERE graduation_year = 2019
ORDER BY studentID DESC;- The GROUP BY clause in SQL is used to group records with the same data, and can be used in conjunction with some aggregate functions to generate summary results from the database.
- The HAD clause in SQL combined with the GROUP BY clause is used to filter records. It’s different from WHERE because the WHERE clause can’t filter aggregate records.
SELECT COUNT(studentId), country
FROM myDB.students
WHERE country != "INDIA"
GROUP BY country
HAVING COUNT(studentID) > 5;What are the UNION, MINUS, and INTERSECT commands?
The UNION operator combines and returns the result set retrieved by two or more SELECT statements. The MINUS operator in
SQL is used to remove duplicates from the result set of the second SELECT query from the result set of the first SELECT query, and then return the first filtered result. The INTERSECT clause in
SQL combines the result set taken by two SELECT statements, one of which matches the other, and then returns the intersection of the result set.
There are certain conditions that need to be met before any of the above statements can be executed in SQL –
- Each SELECT statement in the clause must have the same number of columns
- The columns must also have similar data types
- The columns in each SELECT statement must be in the same order
SELECT name FROM Students /* Fetch the union of queries */
UNION
SELECT name FROM Contacts;
SELECT name FROM Students /* Fetch the union of queries with duplicates*/
UNION ALL
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
MINUS /* that aren't present in contacts */
SELECT name FROM Contacts;SELECT name FROM Students /* Fetch names from students */
INTERSECT /* that are present in contacts as well */
SELECT name FROM Contacts;Write a SQL query to get the Name that exists in the table accounts or the table Registry.
Write a SQL query to get the names that exist in “accounts” but not in the table “registry”.
Write a SQL query to get a “name” from the table “contacts” that is neither in “accounts.name” nor in “registry.name”.
What is a cursor? How do I use the cursor?
A database cursor is a control structure that allows traversal of records in a database. In addition, cursors facilitate post-traversal processing, such as retrieving, adding, and deleting database records. They can be thought of as pointers to a line in a set of lines.
Using SQL cursors:
- DECLARE: the cursor after the declaration of any variable. Cursor declarations must always be associated with a SELECT statement.
- Open the cursor to initialize the result set. The OPEN statement must be called before the rows are fetched from the result set.
- FETCH statement to retrieve and move to the next line in the result set.
- The CLOSE statement is called to deactivate the cursor.
- Finally, use the DEALLOCATE statement to delete the cursor definition and release related resources.
DECLARE @name VARCHAR(50) /* Declare All Required Variables */
DECLARE db_cursor CURSOR FOR /* Declare Cursor Name*/
SELECT name
FROM myDB.students
WHERE parent_name IN ('Sara', 'Ansh')
OPEN db_cursor /* Open cursor and Fetch data into @name */
FETCH next
FROM db_cursor
INTO @name
CLOSE db_cursor /* Close the cursor and deallocate the resources */
DEALLOCATE db_cursorWhat are entities and relationships?
Entities: Entities can be real-world objects, can be tangible or intangible, and can be easily identified. For example, in a university database, students, professors, workers, departments, and projects can all be referred to as entities. Each entity has some associated properties that provide it with an identity.
Relationship: An interrelated relationship or connection between entities. For example – the employee table in the company database can be associated with the payroll table in the same database.
List the different types of relationships in SQL.
- One-to-One – This can be defined as a relationship between two tables, where each record in one table is associated with up to one record in the other.
- One-to-many and many-to-one – This is the most commonly used relationship where a record in one table is associated with multiple records in another table.
- Many-to-many– This is used in situations where multiple instances of both parties are required to define the relationship.
- Self-referencing relationship – Used when a table needs to define a relationship with itself.
What is an alias in SQL?
SQL Interview Question Analysis: Aliases are SQL features that are supported by most, if not all, RDBMS. It is a temporary name that is assigned to a table or table column for a particular SQL query. In addition, aliases can be used as an obfuscation technique to protect the true names of database fields. Table aliases are also known as related names.
An alias is explicitly represented by an AS keyword, but in some cases, the same can be done without it. Still, it’s always a good habit to use AS keywords.
SELECT A.emp_name AS "Employee" /* Alias using AS keyword */
B.emp_name AS "Supervisor"
FROM employee A, employee B /* Alias without AS keyword */
WHERE A.emp_sup = B.emp_id;Write a SQL statement that selects all aliases “Ltd” from the table “Limited”.
What is a View?
A view in SQL is a virtual table based on a SQL statement result set. The view contains rows and columns, just like a real table. A field in a view is a field from one or more real tables in a database.
What is normalization?
Normalization represents the way structured data is effectively organized in a database. It includes creating tables, establishing relationships between them, and defining rules for those relationships. Inconsistencies and redundancies can be checked against these rules, increasing the flexibility of the database.
What is denormalization?
Denormalization is the reverse process of normalization, which converts a normalized pattern into a pattern with redundant information. Improve performance by using redundancy and keeping redundant data consistent. The reason for performing denormalization is the overhead that over-normalizing the structure incurs in the query processor.
What are the common interview questions SQL: What are the various forms of normalization?
Paradigms are used to eliminate or reduce redundancies in database tables. The different forms are as follows:
- First Normal Form:
If every attribute in the relationship is a single-valued attribute, then the relationship is the first normal form. If a relationship contains a composite or multi-valued attribute, it violates the first normal paradigm. Let’s consider the following student table. Each student at the table has a name, his/her address, and the books they have issued from the public library –
Students Table
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter), Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho), Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward), Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
As we have observed, each record in the Books Issued field has multiple values, and to convert it to 1NF, it must be parsed into a separate record for each published book. Check the table below in 1NF form –
Student Table (1st Paradigm)
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter) | Ms. |
| Sara | Amanora Park Town 94 | Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho) | Mr. |
| Ansh | 62nd Sector A-10 | Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward) | Mrs. |
| Sara | 24th Street Park Avenue | Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
- Second Paradigm:
A relationship is second normal if it satisfies the conditions of the first normal and does not contain any partial dependencies. 2A relationship in NF has no partial dependency, i.e., it does not have a non-primary property that depends on any appropriate subset of any candidate keys for the table. In general, specifying a single-column primary key is the solution to the problem. Example-
Example 1 – Consider the example above. We can observe that the Students table in the form of 1NF has a candidate key of the form [Student, Address] that uniquely identifies all records in the table. The Field Books Issued (non-primary attribute) depends in part on the Student field. Therefore, the table is not in 2NF. To translate this into a second normal form, we split the table into two, while specifying a new primary key attribute to identify the individual records in the student table. The foreign key constraint will be set to ensure referential integrity on the other machine.
Student Table (2nd Paradigm)
| Student_ID | Student | Address | Salutation |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | Ms. |
| 2 | Ansh | 62nd Sector A-10 | Mr. |
| 3 | Sara | 24th Street Park Avenue | Mrs. |
| 4 | Ansh | Windsor Street 777 | Mr. |
Book List (Second Paradigm)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Example 2 – Consider the following dependencies related to R(W,X,Y,Z).
WX -> Y [W and X together determine Y]
XY -> Z [X and Y together determine Z] Here, WX is the only candidate and there is no partial dependency, i.e., any true subset of WX does not determine any non-primary properties in the relationship.
- Third Paradigm
If a relationship satisfies the conditions of the second normal form, and there is no transitive dependency between non-primary properties, i.e., all non-primary properties are determined only by the relationship and not by any other non-primary property.
Example 1 – Consider the student table in the example above. As we have observed, the Students table in the form of 2NF has a single candidate key, Student_ID (primary key), which uniquely identifies all records in the table. However, the field salutation (non-primary attribute) depends on the student field and not on the candidate key. Therefore, the table is not in 3NF. To translate this into the third normal form, we’ll divide the table into two parts again, while assigning a new foreign key constraint to identify the names of the individual records in the student table. The same primary key constraint is set on the Salutations table to uniquely identify each record.
Student Sheet (3rd Paradigm)
| Student_ID | Student | Address | Salutation_ID |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | 1 |
| 2 | Ansh | 62nd Sector A-10 | 2 |
| 3 | Sara | 24th Street Park Avenue | 3 |
| 4 | Ansh | Windsor Street 777 | 1 |
Book List (3rd Paradigm)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Scales of Names (Third Normal)
| Salutation_ID | Salutation |
|---|---|
| 1 | Ms. |
| 2 | Mr. |
| 3 | Mrs. |
Example 2 – Consider the following dependencies related to R(P,Q,R,S,T).
P -> QR [P together determine C]
RS -> T [B and C together determine D]
Q -> S
T -> P For the above relationship that exists in 3NF, the possible candidate in the above relationship should be {P, RS, QR, T}.
- Boyce-Codd paradigm
If the third normal and the conditions of each function dependency are satisfied, then the relationship is the Boyce-Codd paradigm and Left-Hand-Side is super critical. In other words, the relationship in BCNF has a nontrivial function dependency of the form X –> Y, so X is always a superkey. For example – in the example above, Student_ID as the unique unique identifier of the student table, the Salutation_ID of the Salutations table, so these tables exist in the BCNF. The same cannot be said for the Books table, and there can be several books with the same title and the same Student_ID.
WHAT ARE TRUNCATE, DELETE, AND DROP STATEMENTS?
The DELETE statement is used to remove rows from a table.
DELETE FROM Candidates
WHERE CandidateId > 1000;The TRUNCATE command is used to delete all rows in a table and free up space that contains the table.
TRUNCATE TABLE Candidates;The DROP command is used to delete an object from the database. If you delete a table, all rows in that table are deleted, and the table structure is removed from the database.
DROP TABLE Candidates;Write a SQL statement to erase the table “temporary” from memory.
Write a SQL query to remove the first 1000 records from table ‘Temporary’ based on ‘id’.
Write a SQL statement to remove the table ‘Temporary’ while leaving its relationship intact.
What is the difference between DROP and TRUNCATE statements?
If a table is deleted, everything related to that table is also deleted. This includes – relationships with other tables defined on the table, integrity checks and constraints, access permissions, and other authorizations that the table has. To create and use the table again in its original form, all of these relationships, checks, constraints, privileges, and relationships need to be redefined. However, if the table is truncated, none of the above problems exist, and the table retains its original structure.
What is the difference between DELETE and TRUNCATE statements?
The TRUNCATE command is used to delete all rows from the table and space in the containing free table.
The DELETE command removes only rows from the table based on the condition given in the WHERE clause or all rows from the table if no condition is specified. But it doesn’t free up space that contains tables.
SQL Collection of Common Interview Questions and Answers: What Are Aggregate Functions and Scalar Functions?
An aggregate function performs an operation on a set of values to return a single scalar value. Aggregate functions are typically used with the GROUP BY and HAVING clauses of the SELECT statement. The following are the widely used SQL aggregate functions:
- AVG() – Calculates the average of a set of values.
- COUNT() – COUNTS THE TOTAL NUMBER OF RECORDS IN A SPECIFIC TABLE OR VIEW.
- MIN() – Calculates the minimum value of a set of values.
- MAX()—Calculates the maximum value of a set of values.
- SUM() – Calculates the sum of a set of values.
- FIRST() – GETS THE FIRST ELEMENT IN THE SET OF VALUES.
- LAST() – Gets the last element in the value collection.
Note: All of the above aggregate functions ignore NULL values except for the COUNT function.
The scalar function returns a single value based on the input value. The following are the widely used SQL scalar functions:
- LEN()—Calculates the total length of a given field (column).
- UCASE() – Converts a collection of string values to uppercase characters.
- LCASE() – Converts a collection of string values to lowercase characters.
- MID()—Extracts a substring from a collection of string values in the table.
- CONCAT() – CONCATENATE TWO OR MORE STRINGS.
- RAND()—Generates a set of random numbers of a given length.
- ROUND() – CALCULATES THE ROUNDED VALUE OF A NUMERIC FIELD (OR DECIMAL POINT VALUE).
- NOW()—Returns the current date and time.
- FORMAT() – SETS THE FORMAT FOR DISPLAYING A COLLECTION OF VALUES.
What is a custom function? What are its types?
User-defined functions in SQL, like those in any other programming language, can accept parameters, perform complex calculations, and return values. They are written to reuse logic when needed. There are two types of SQL user-defined functions:
- Scalar Functions: As mentioned earlier, user-defined scalar functions return a single scalar value.
- Table-valued function: A user-defined table-valued function returns a table as output.
- Inline: Returns a table data type based on a single SELECT statement.
- Multi-statement: Returns a tabular result set, but unlike inline, you can use multiple SELECT statements within the function body.
What is OLTP?
SQL Interview Question Analysis: OLTP stands for Online Transaction Processing, which is a type of software application that can support transaction-oriented programs. An essential attribute of an OLTP system is its ability to maintain concurrency. To avoid a single point of failure, OLTP systems are often decentralized. These systems are usually designed for a large number of users who make short-term trades. Database queries are often simple, require sub-second response times, and return relatively few records. This is an in-depth look at how the OLTP system works [note – the number is not important for an interview] –
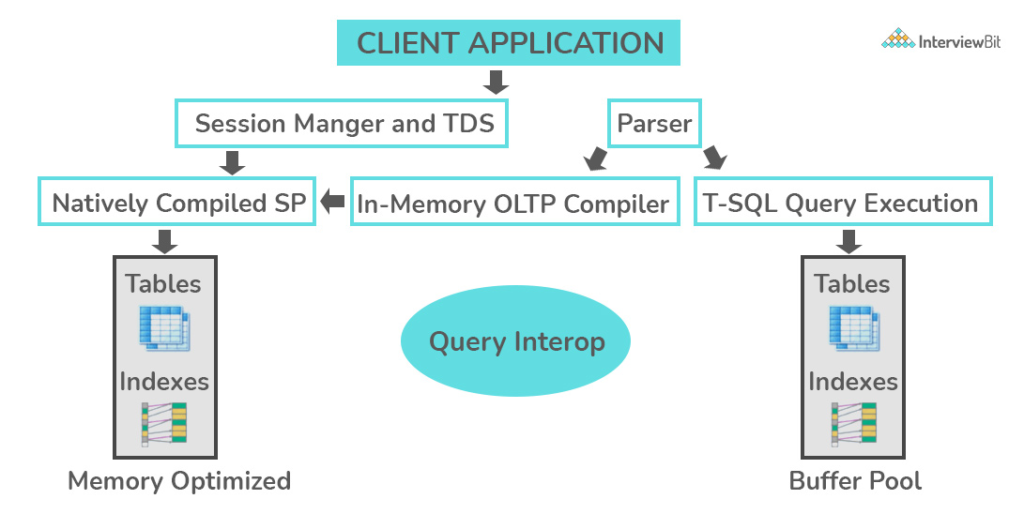
What is the difference between OLTP and OLAP?
OLTP stands for Online Transaction Processing and is a class of software applications that support transaction-oriented programs. An important attribute of an OLTP system is its ability to maintain concurrency. OLTP systems typically follow a decentralized architecture to avoid a single point of failure. These systems are typically designed for a large number of end-users who make short-term transactions. The queries involved in such databases are generally simple, require fast response times, and return relatively few records. The number of transactions per second is a valid measure for such systems.
OLAP stands for Online Analytical Processing and is a class of software programs that is characterized by a relatively low frequency of online transactions. Queries are often too complex and involve a bunch of aggregates. For OLAP systems, effectiveness measures are highly dependent on response time. Such systems are widely used for data mining or maintaining aggregated historical data, often in a multidimensional pattern.
What is finishing? What are the different types of proofreading sensitivity?
A collation is a set of rules that determine how data is sorted and compared. Rules that define the correct sequence of characters are used to sort the character data. It contains options for specifying case-sensitive, accent marks, kana character types, and character widths. Here are the different types of grooming sensitivity:
- Case-sensitive: A and a are handled differently.
- Accent sensitivity: A and á are handled differently.
- Kana sensitivity: The Japanese kana characters hiragana and katakana are treated differently.
- Width sensitivity: The same character represented by a single byte (half-width) and a double-byte (full-width) are handled differently.
What is a stored procedure?
Stored procedures are subroutines that can be used by applications that access relational database management systems (RDBMS). Such programs are stored in a database data dictionary. The only disadvantage of a stored procedure is that it can only be executed in the database and takes up more memory in the database server. It also provides a sense of security and functionality, as users who don’t have direct access to the data can gain access through stored procedures.
DELIMITER $$
CREATE PROCEDURE FetchAllStudents()
BEGIN
SELECT * FROM myDB.students;
END $$
DELIMITER ;What is a recursive stored procedure?
A stored procedure that calls itself before a boundary condition is reached is called a recursive stored procedure. This recursive function helps programmers deploy the same set of code multiple times when needed. Some SQL programming languages limit recursion depth to prevent an infinite loop of procedure calls from causing a stack overflow, which slows down the system and can lead to a system crash.
DELIMITER $$ /* Set a new delimiter => $$ */
CREATE PROCEDURE calctotal( /* Create the procedure */
IN number INT, /* Set Input and Ouput variables */
OUT total INT
) BEGIN
DECLARE score INT DEFAULT NULL; /* Set the default value => "score" */
SELECT awards FROM achievements /* Update "score" via SELECT query */
WHERE id = number INTO score;
IF score IS NULL THEN SET total = 0; /* Termination condition */
ELSE
CALL calctotal(number+1); /* Recursive call */
SET total = total + score; /* Action after recursion */
END IF;
END $$ /* End of procedure */
DELIMITER ; /* Reset the delimiter */How do I create an empty table with the same structure as another table?
By using the INTO operator to extract the records of one table into a new table, while fixing the WHERE clause to false for all records, you can cleverly create empty tables with the same structure. As a result, SQL prepares a new table with a repeating structure to accept the acquired records, but since the WHERE clause is in play, no records are fetched, so nothing is inserted into the new table.
SELECT * INTO Students_copy
FROM Students WHERE 1 = 2;What is pattern matching in SQL?
If you don’t know what the word should be, SQL pattern matching provides a pattern search in your data. This type of SQL query uses wildcards to match string patterns instead of writing out the exact words. The LIKE operator is used in conjunction with the SQL wildcard to get the information you need.
- Perform a simple search using the % wildcard
% wildcards match zero or more characters of any type and can be used to define wildcards before and after the pattern. Search your database for students whose names begin with the letter K:
SELECT *
FROM students
WHERE first_name LIKE 'K%'- Use the NOT keyword omitted pattern
Use the NOT keyword to select records that don’t match the pattern. This query returns all students whose names don’t start with K.
SELECT *
FROM students
WHERE first_name NOT LIKE 'K%'- Use the % wildcard match pattern twice anywhere
Search the database for students with a K in their name.
SELECT *
FROM students
WHERE first_name LIKE '%Q%'- Use the _wildcard to match the pattern of a specific location
_ wildcard character matches exactly one character of any type. It can be used in conjunction with the % wildcard. This query gets all students with the letter K in the third position of their name.
SELECT *
FROM students
WHERE first_name LIKE '__K%'- Patterns that match a specific length
_ wildcards play an important role as a limiting role when matching a character exactly. It limits the length and position of the matching results. For example-
SELECT * /* Matches first names with three or more letters */
FROM students
WHERE first_name LIKE '___%'
SELECT * /* Matches first names with exactly four characters */
FROM students
WHERE first_name LIKE '____'PostgreSQL Interview Questions
What is PostgreSQL?
Originally known as Postgres, PostgreSQL was developed in 1986 by a team led by computer science professor Michael Stonebraker. It is designed to help developers build enterprise-grade applications by making the system fault-tolerant to maintain data integrity. As a result, PostgreSQL is an enterprise-grade, flexible, robust, open-source, and object-relational DBMS that supports flexible workloads and handles concurrent users. It has always been supported by the global developer community. Because of its fault tolerance, PostgreSQL is popular among developers.
How are indexes defined in PostgreSQL?
Indexes are built-in functions in PostgreSQL that are used by queries to perform searches on tables in a database more efficiently. Considering that you have a table with thousands of records, and you have the following query, only a handful of records can satisfy the condition, it will take a lot of time to search and return those rows that match this condition because the engine has to do this to perform a search operation on each individual to check for this condition. This is undoubtedly inefficient for systems that process massive amounts of data. Now, if this system has an index on the columns that our app searches, it can use an efficient way to identify matching rows by just traversing a few levels. This is called an index.
Select * from some_table where table_col=120How would you change the data type of a column?
This can be done by using the ALTER TABLE statement as follows:
Syntax:
ALTER TABLE tname
ALTER COLUMN col_name [SET DATA] TYPE new_data_type;What is the command to create a database in PostgreSQL?
The first step in using PostgreSQL is to create a database. This is done by using the createdb command, as shown below:
After running the above command, if the database is created successfully, the following message is displayed:createdb db_name
CREATE DATABASEHow do I start, restart, and stop a PostgreSQL server?
- To start the PostgreSQL server, we run:
service postgresql start- Once the server is successfully started, we get the following information:
Starting PostgreSQL: ok- To restart the PostgreSQL server, we run:
service postgresql restartAfter the server is successfully restarted, we receive the following message:
Restarting PostgreSQL: server stopped
ok- To stop the server, we run the following command:
service postgresql stopAfter a successful stop, we receive a message:
Stopping PostgreSQL: server stopped
okWhat is a partitioned table in PostgreSQL?
A partitioned table is a logical structure used to divide a large table into smaller structures called partitions. This approach is used to effectively improve query performance when working with large database tables. To create a partition, you need to define a key called a partition key, which is usually a table column or an expression, and you need to define a partition method. Postgres provides three built-in partitioning methods:
- Range partitioning: This method is done by partitioning based on a series of values. This method is most commonly used in date fields to get monthly, weekly, or yearly data. In the case of an edge case where the image value falls at the end of the range, for example, if the range of partition 1 is 10-20, the range of partition 2 is 20-30, and the given value is 10, then 10 belongs to the second partition and not the first partition.
- List Partitioning: This method is used to partition based on a list of known values. It is most commonly used when we have a key with a categorical value. For example, get sales data based on a region, a country, a city, or a state.
- Hash partitioning: This method uses a hash function on the partition key. This is done without specific requirements for data segmentation and is used to access the data individually. For example, if you want to access product-specific data, then using a hash partition will result in the dataset we need.
The type of partition key and the type of method used for partitioning determine how positive the performance and manageability level of a partitioned table is.
Define a token in PostgreSQL?
Tags in PostgreSQL can be keywords, identifiers, literals, constants, quotation mark identifiers, or any symbol with a unique personality. They may or may not be separated by spaces, line breaks, or tabs. If tags are keywords, they are usually commands with useful meanings. Tokens are referred to as the building blocks of any PostgreSQL code.
What is the importance of TRUNCATE statements?
TRUNCATE TABLE name_of_tablestatements effectively and quickly remove data from a table.
The truncate statement can also be used to reset the value of the identity column, as well as data cleansing, as follows:
TRUNCATE TABLE name_of_table
RESTART IDENTITY;We can also delete data from multiple tables at once by mentioning a statement with comma-separated table names, like this:
TRUNCATE TABLE
table_1,
table_2,
table_3;What is the capacity of a table in PostgreSQL?
The maximum size of PostgreSQL is 32TB.
Define the sequence.
Sequences are schema-bound, user-defined objects that help generate integer sequences. This is most commonly used to generate values for the identity column in the table. We can create a sequence using a statement that looks like this:CREATE SEQUENCE
CREATE SEQUENCE serial_num START 100;To get the next number 101 from the sequence, we use the nextval() method as follows:
SELECT nextval('serial_num');We can also use this sequence when inserting a new record using the INSERT command:
INSERT INTO ib_table_name VALUES (nextval('serial_num'), 'interviewbit');What are string constants in PostgreSQL?
They are sequences of characters bound within single quotes. These are used during data insertion or updating of characters in the database.
There are special string constants that are referenced in dollars. Syntax: Tags in constants are optional, and when we don’t specify tags, constants are called binary string literals.$tag$<string_constant>$tag$
How do I get a list of all databases in PostgreSQL?
This can be done by using the command-> backslash followed by the lowercase letter L.\l
How do I delete a database in PostgreSQL?
This can be done by using the DROP DATABASE command, as shown in the following syntax:
DROP DATABASE database_name;If the database was successfully deleted, the following message is displayed:
DROP DATABASEWhat are ACID properties? Is PostgreSQL ACID compliant?
SQL Interview Question Analysis: ACID stands for atomicity, consistency, isolation, and persistence. They are database transaction properties that guarantee data validity in the event of errors and failures.
- Atomicity: This property ensures that the transaction is completed in an all-or-nothing manner.
- Consistency: This ensures that updates made to the database are valid and follow rules and restrictions.
- Isolation: This property ensures the integrity of a transaction that is visible to all other transactions.
- Persistence: This property ensures that committed transactions are permanently stored in the database.
PostgreSQL conforms to the ACID attribute.
Can you explain the architecture of PostgreSQL?
- The architecture of PostgreSQL follows a client-server model.
- The server-side consists of a background process manager, a query processor, utilities, and a shared memory space that work together to build a PostgreSQL instance that can access data. The client application executes tasks connected to this instance and requests data processing from the service. The client can be a GUI (graphical user interface) or a web application. The most commonly used client for PostgreSQL is pgAdmin.
How to understand multi-version concurrency control?
MVCC, or Multi-Version Concurrency Control, is used to avoid unnecessary database locks when 2 or more requests simultaneously attempt to access or modify data. This ensures that the time delay for users to log in to the database is avoided. When anyone tries to access the content, the transaction is recorded.
What is your understanding of the enable-debug command?
The command enable-debug is used to enable compilation of all libraries and applications. When this feature is enabled, system processes are hindered and the size of the binary file is often increased as well. Therefore, it is not recommended to enable this feature in a production environment. This is most commonly used by developers to debug bugs in scripts and help them find problems. For more information on how to debug, you can refer here.
How do you check for rows that were affected as part of a previous transaction?
The SQL standard states that the following three phenomena should be prevented when concurrently transacting. The SQL standard defines 4 levels of transaction isolation to handle these phenomena.
- Dirty reads: If a transaction reads data that was written as a result of concurrent uncommitted transactions, those reads are called dirty reads.
- Phantom Read: This occurs when two identical queries return different rows when executed separately. For example, if transaction A retrieves certain sets of rows that match the search criteria. Suppose another transaction B retrieves a new row in addition to the row previously obtained for the same search criteria. The results are different.
- Non-repeatable read: This occurs when a transaction tries to read the same row multiple times and gets a different value each time due to concurrency. This happens when another transaction updates that data and our current transaction gets that updated data, resulting in a different value.
To address these issues, SQL Standard defines 4 standard isolation levels. They are as follows:
- Read Uncommitted – The lowest level of isolation. Here, the transaction is not isolated and can read data that is not committed by other transactions, resulting in dirty reads.
- Read Committed – This level ensures that read data is committed at any split point in the read time. Therefore, dirty readings are avoided here. This level uses a read/write lock on the current row to prevent read/write/update/delete of that row while the current transaction is being operated.
- Repeatable Read – The strictest level of isolation. This holds read and write locks for all the rows it operates. As a result, non-repeatable reads are avoided because rows cannot be read, written, updated, or deleted by other transactions.
- Serializable – The highest of all isolation levels. This guarantees that the execution is serializable, where the execution of any concurrent operation is guaranteed to appear as a serial execution.
The following table clearly illustrates the types of unwanted reads that are avoided by the level:
| Isolation level | Dirty read | Phantom reading | It cannot be read repeatedly |
|---|---|---|---|
| Read not submitted | It can happen | It can happen | It can happen |
| Read committed | It’s not going to happen | It can happen | It can happen |
| Repeatable reads | It’s not going to happen | It can happen | It’s not going to happen |
| Serializable | It’s not going to happen | It’s not going to happen | It’s not going to happen |
What can you say about WAL (Write Ahead Logging)?
Write Ahead Logging is a feature that improves database reliability by logging changes before any changes are made to the database. This ensures that we have enough information in the event of a database crash by helping to determine the point at which work is completed and providing a starting point from the point at which work is stopped.
What are the main drawbacks of using the DROP TABLE command to remove data from an existing table?
DROP TABLEThe command deletes the complete data from the table, as well as the complete table structure. If our requirement only requires the deletion of data, then we need to recreate the table to store the data in it. In this case, it is recommended to use the TRUNCATE command.
How do I use regular expressions for case-insensitive search in PostgreSQL?
To perform a case-insensitive match using a regular expression, we can use a POSIX expression from the pattern matching operator. For example:(~*)
'interviewbit' ~* '.*INTervIewBit.*'How would you back up a database in PostgreSQL?
We can achieve this by using the pg_dump tool to dump all the object contents in the database into a single file. The steps are as follows:
Step 1: Navigate to the bin folder of the PostgreSQL installation path.
C:\>cd C:\Program Files\PostgreSQL\10.0\binStep 2: Execute the pg_dump program to dump the data to the .tar folder as follows:
pg_dump -U postgres -W -F t sample_data > C:\Users\admin\pgbackup\sample_data.tarThe database dump is stored in a sample_data.tar file in the specified location.
Does PostgreSQL support full-text search?
What are the common interview questions for SQL? Full-text search is a method of searching a full-text-based database for a single document or collection of documents stored on a computer. This is primarily supported in advanced database systems such as SOLR or ElasticSearch. However, the feature exists but is very basic in PostgreSQL.
What is a parallel query in PostgreSQL?
Parallel query support is a feature available in PostgreSQL for designing query plans that take advantage of multiple CPU processors to execute queries faster.
Distinguish between submissions and checkpoints.
The commit action ensures that the data consistency of the transaction is maintained and ends the current transaction in the section. Commit adds a new record to the log describing the COMMIT in memory. Checkpoints, on the other hand, are used to write all changes committed to disk to the SCN, which are saved in the data file header and control file.
SQL Common Interview Questions and Answers Collection Conclusion:
SQL is a database language. It has a wide scope and powerful features to create and manipulate various database objects using commands such as CREATE, ALTER, DROP, as well as loading database objects using commands such as INSERT. It also provides the option to use commands such as DELETE, TRUNCATE, etc., for data manipulation, and retrieve data efficiently using cursor commands such as FETCH, SELECT, etc. There are many such commands that provide a lot of control for the programmer to interact with the database in an efficient way without wasting a lot of resources. SQL has become so widespread that almost every programmer relies on it for the storage functions of their applications, making it an exciting language to learn.
PostgreSQL is an open-source database system with extremely powerful and sophisticated ACID, indexing, and transaction support that is popular among the developer community.