Use Tensorflow and Keras in Python to build deep learning models (using embedding and loop layers) for different text classification problems, such as sentiment analysis or 20 newsgroup classification.
Python implements text classification using Tensorflow 2 and Keras – Text classification is one of the important and common tasks in supervised machine learning. It’s about assigning a category (a class) to documents, articles, books, reviews, tweets, or anything that involves text. It is the core task of natural language processing.
Many applications seem to use text classification as their primary task, and examples include spam filtering, sentiment analysis, speech tagging, language detection, and many more.
How does Python classify text? In this tutorial, we’ll use Tensorflow in Python to build a text classifier model using RNN, and we’ll use the IMDB review dataset with 50,000 real-world movie reviews and their sentiment (positive or negative). At the end of this tutorial, I’ll show you how to integrate your own dataset so that you can train a model on it.
Although we’re using a sentiment analysis dataset, this tutorial is designed to perform text classification for any task, and if you want to perform sentiment analysis right away, check out this tutorial.
If you want to use a state-of-the-art transformer model, such as BERT, check out this tutorial where we fine-tune BERT for a custom dataset.
Python Text Classification Example – First, you need to install the following libraries:
pip3 install tqdm numpy tensorflow==2.0.0 sklearnNow open a new Python notebook or file and continue, let’s import the modules we need:
from tqdm import tqdm
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Dense, Dropout, LSTM, Embedding, Bidirectional
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import TensorBoard
from sklearn.model_selection import train_test_split
import numpy as np
from glob import glob
import random
import osData preparation
Now before we load our data into Python, you need to download the dataset here, and you’ll see that two files exist, reviews.txt which contain a movie review for each line, and labels.txt hold their corresponding tags.
The following functions load and preprocess datasets:
def load_imdb_data(num_words, sequence_length, test_size=0.25, oov_token=None):
# read reviews
reviews = []
with open("data/reviews.txt") as f:
for review in f:
review = review.strip()
reviews.append(review)
labels = []
with open("data/labels.txt") as f:
for label in f:
label = label.strip()
labels.append(label)
# tokenize the dataset corpus, delete uncommon words such as names, etc.
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(reviews)
X = tokenizer.texts_to_sequences(reviews)
X, y = np.array(X), np.array(labels)
# pad sequences with 0's
X = pad_sequences(X, maxlen=sequence_length)
# convert labels to one-hot encoded
y = to_categorical(y)
# split data to training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=1)
data = {}
data["X_train"] = X_train
data["X_test"]= X_test
data["y_train"] = y_train
data["y_test"] = y_test
data["tokenizer"] = tokenizer
data["int2label"] = {0: "negative", 1: "positive"}
data["label2int"] = {"negative": 0, "positive": 1}
return dataHow does Python classify text? There’s a lot of stuff here, and this function does the following:
- It loads the dataset from the previously mentioned file.
- After that, it uses the utility Tokenizer class of Keras, which helps us to automatically remove all punctuation, mark the corpus, remove rare words such as names, convert text sentences into a sequence of numbers (each word corresponds to a number).
- We already know that neural networks require fixed-length inputs, and since comments don’t have words of the same length, we need a way to fix the length of a sequence to a fixed size. pad_sequences () function comes in handy, we tell it that we only want to say 300 words in each comment (parameter), it will remove words that exceed that number and will fill the comments below with 0 300.
maxlen - We use the Keras’ to_categorical() function to encode the label alone, which is a binary classification, so it converts the label 0 to the [1,0] vector, and 1 to [0,1]. But in general, it converts categorical labels into fixed-length vectors.
- After that, we use sklearn’s train_test_split() function to split our dataset into a training set and a test set, and use the data dictionary to add everything we need during the training process, i.e., the dataset, tokenizer, and label encoding dictionary.
Build a model
Python implements text classification using Tensorflow 2 and Keras: now that we know how to load the dataset, let’s build our model.
We’ll use the embedding layer as the first layer of the model. Embedding has proven useful in mapping categorical variables (in this case, words) to continuous numeric vectors, and it is widely used for natural language processing tasks.
More precisely, we’ll use pre-trained GloVe word vectors, which are pre-trained vectors that map each word to a vector of a specific size. This size parameter is often referred to as the embedding size, although gloves are used for 50, 100, 200, or 300 embedding size carriers. In this tutorial, we’ll try all of them and see which one works best. Also, two words with the same meaning tend to have very close vectors.
The second layer will be the recurrent layer, where you can choose any recurrent unit you want, including LSTM, GRU, or even just SimpleRNN, and we will see again which is better than the others.
The last layer should be a dense layer with N neurons, and N should be the same number of classes for your dataset. In the case of positive/negative sentiment analysis, it should be 2.
The overall architecture of the model is shown in the following diagram (taken from the Spam Classifier tutorial):
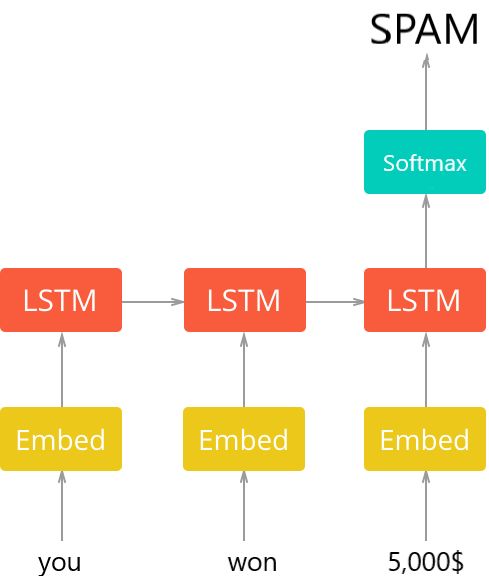
Python text classification example: Now you need to download the pre-trained GloVe (download it here), and when you’re done, extract them all into the data folder (you’ll find different vectors for different embedding sizes), and load these vectors with the following function:
def get_embedding_vectors(word_index, embedding_size=100):
embedding_matrix = np.zeros((len(word_index) + 1, embedding_size))
with open(f"data/glove.6B.{embedding_size}d.txt", encoding="utf8") as f:
for line in tqdm(f, "Reading GloVe"):
values = line.split()
# get the word as the first word in the line
word = values[0]
if word in word_index:
idx = word_index[word]
# get the vectors as the remaining values in the line
embedding_matrix[idx] = np.array(values[1:], dtype="float32")
return embedding_matrixNow we need a function to create the model from scratch, given the hyperparameters:
def create_model(word_index, units=128, n_layers=1, cell=LSTM, bidirectional=False,
embedding_size=100, sequence_length=100, dropout=0.3,
loss="categorical_crossentropy", optimizer="adam",
output_length=2):
"""Constructs a RNN model given its parameters"""
embedding_matrix = get_embedding_vectors(word_index, embedding_size)
model = Sequential()
# add the embedding layer
model.add(Embedding(len(word_index) + 1,
embedding_size,
weights=[embedding_matrix],
trainable=False,
input_length=sequence_length))
for i in range(n_layers):
if i == n_layers - 1:
# last layer
if bidirectional:
model.add(Bidirectional(cell(units, return_sequences=False)))
else:
model.add(cell(units, return_sequences=False))
else:
# first layer or hidden layers
if bidirectional:
model.add(Bidirectional(cell(units, return_sequences=True)))
else:
model.add(cell(units, return_sequences=True))
model.add(Dropout(dropout))
model.add(Dense(output_length, activation="softmax"))
# compile the model
model.compile(optimizer=optimizer, loss=loss, metrics=["accuracy"])
return modelHow does Python classify text? I know, there are a lot of arguments in this function. Well, in order to test various parameters, this feature will be flexible on all the provided parameters. Let’s explain:
word_index: This is a dictionary that maps each word to its corresponding index number, which is generated by the aforementioned Tokenizer object.units: This is the number of neurons in each recirculating layer, the default is 128, but you can use any number you want, note that the more units, the more weights to adjust, and therefore the slower the process will be in training.n_layers: This is the number of layers of loops we want to use, and 1 is a good place to start.cell: If you want to use the recurrent cell, LSTM is a good choice.bidirectional: This is a Boolean variable that indicates whether or not we are using a bidirectional loop layer.embedding_size: The size of the embedding vector we mentioned earlier, we will experiment with various sizes.sequence_length: Enter the number of marker words on each text sample of the neural network, which we will also experiment with with this parameter.dropout: It is the probability of training a given node on a layer, and it is useful for reducing overfitting. 40% is great for this, but try tweaking it and see if it performs better.loss: This is the loss function used for training, and by default we use the categorical cross-entropy function.optimizer: To use the optimizer function, we’re using ADAM here.output_length: This is the number of neurons used in the last layer, since we only use positive and negative emotions classification, it must be 2.
When you look closely, you’ll notice that I’m using the Embedding class with parameters, which specifies the pre-training weights we just downloaded, and we also set them to False, so the vectors don’t change the training process at all during this time.weightstrainable
If your dataset uses a different language than English, make sure you find an embedding vector for the language you’re using, if not, you shouldn’t set the weights parameter at all, and you need to set it to True in order to train the parameters of the vector from scratch, check this page for word vectors for your language.trainable
Train the model
Python implements text classification using Tensorflow 2 and Keras – now to start training, we need to define all the previously mentioned hyperparameters and more:
# max number of words in each sentence
SEQUENCE_LENGTH = 300
# N-Dimensional GloVe embedding vectors
EMBEDDING_SIZE = 300
# number of words to use, discarding the rest
N_WORDS = 10000
# out of vocabulary token
OOV_TOKEN = None
# 30% testing set, 70% training set
TEST_SIZE = 0.3
# number of CELL layers
N_LAYERS = 1
# the RNN cell to use, LSTM in this case
RNN_CELL = LSTM
# whether it's a bidirectional RNN
IS_BIDIRECTIONAL = False
# number of units (RNN_CELL ,nodes) in each layer
UNITS = 128
# dropout rate
DROPOUT = 0.4
### Training parameters
LOSS = "categorical_crossentropy"
OPTIMIZER = "adam"
BATCH_SIZE = 64
EPOCHS = 6
def get_model_name(dataset_name):
# construct the unique model name
model_name = f"{dataset_name}-{RNN_CELL.__name__}-seq-{SEQUENCE_LENGTH}-em-{EMBEDDING_SIZE}-w-{N_WORDS}-layers-{N_LAYERS}-units-{UNITS}-opt-{OPTIMIZER}-BS-{BATCH_SIZE}-d-{DROPOUT}"
if IS_BIDIRECTIONAL:
# add 'bid' str if bidirectional
model_name = "bid-" + model_name
if OOV_TOKEN:
# add 'oov' str if OOV token is specified
model_name += "-oov"
return model_nameSo far, I’ve set the best parameters, and I’ve found that the get_model_name() function is generating unique model names based on the parameters, which is very useful when comparing various parameters on the TensorBoard.
Let’s put everything together and start training our model:
# create these folders if they does not exist
if not os.path.isdir("results"):
os.mkdir("results")
if not os.path.isdir("logs"):
os.mkdir("logs")
if not os.path.isdir("data"):
os.mkdir("data")
# dataset name, IMDB movie reviews dataset
dataset_name = "imdb"
# get the unique model name based on hyper parameters on parameters.py
model_name = get_model_name(dataset_name)
# load the data
data = load_imdb_data(N_WORDS, SEQUENCE_LENGTH, TEST_SIZE, oov_token=OOV_TOKEN)
# construct the model
model = create_model(data["tokenizer"].word_index, units=UNITS, n_layers=N_LAYERS,
cell=RNN_CELL, bidirectional=IS_BIDIRECTIONAL, embedding_size=EMBEDDING_SIZE,
sequence_length=SEQUENCE_LENGTH, dropout=DROPOUT,
loss=LOSS, optimizer=OPTIMIZER, output_length=data["y_train"][0].shape[0])
model.summary()
# using tensorboard on 'logs' folder
tensorboard = TensorBoard(log_dir=os.path.join("logs", model_name))
# start training
history = model.fit(data["X_train"], data["y_train"],
batch_size=BATCH_SIZE,
epochs=EPOCHS,
validation_data=(data["X_test"], data["y_test"]),
callbacks=[tensorboard],
verbose=1)
# save the resulting model into 'results' folder
model.save(os.path.join("results", model_name) + ".h5")This will take a few minutes to train, and here’s my execution output after the training is complete:
Reading GloVe: 400000it [00:17, 23047.55it/s]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 300, 300) 37267200
_________________________________________________________________
lstm (LSTM) (None, 128) 219648
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 2) 258
=================================================================
Total params: 37,487,106
Trainable params: 219,906
Non-trainable params: 37,267,200
_________________________________________________________________
Train on 35000 samples, validate on 15000 samples
Epoch 1/6
35000/35000 [==============================] - 186s 5ms/sample - loss: 0.4359 - accuracy: 0.7919 - val_loss: 0.2912 - val_accuracy: 0.8788
Epoch 2/6
35000/35000 [==============================] - 179s 5ms/sample - loss: 0.2857 - accuracy: 0.8820 - val_loss: 0.2608 - val_accuracy: 0.8919
Epoch 3/6
35000/35000 [==============================] - 175s 5ms/sample - loss: 0.2501 - accuracy: 0.8985 - val_loss: 0.2472 - val_accuracy: 0.8977
Epoch 4/6
35000/35000 [==============================] - 174s 5ms/sample - loss: 0.2184 - accuracy: 0.9129 - val_loss: 0.2525 - val_accuracy: 0.8997
Epoch 5/6
35000/35000 [==============================] - 185s 5ms/sample - loss: 0.1918 - accuracy: 0.9246 - val_loss: 0.2576 - val_accuracy: 0.9035
Epoch 6/6
35000/35000 [==============================] - 188s 5ms/sample - loss: 0.1598 - accuracy: 0.9391 - val_loss: 0.2494 - val_accuracy: 0.9004The replication is fantastic, after 6 epochs of training, it achieves about 90% accuracy.
Test the model
Working with the model is very simple, and the following function uses the model.predict() method to generate the output:
def get_predictions(text):
sequence = data["tokenizer"].texts_to_sequences([text])
# pad the sequences
sequence = pad_sequences(sequence, maxlen=SEQUENCE_LENGTH)
# get the prediction
prediction = model.predict(sequence)[0]
return prediction, data["int2label"][np.argmax(prediction)]As you can see, in order to generate the prediction correctly, we need to convert the text into a sequence using the tokenizer we used earlier, then fill the sequence so that it is a fixed-length sequence, and then we use the model to generate the output. predict() method, let’s try this model:
text = "The movie is awesome!"
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)Output:
Output vector: [0.3001343 0.69986564]
Prediction: positiveLet’s use another text:
text = "The movie is bad."
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)Copy Output:
Output vector: [0.92491007 0.07508987]
Prediction: negativeTo be sure, this is a negative sentiment with a confidence level of about 92%. Let’s make it more challenging:
text = "Not very good, but pretty good try."
output_vector, prediction = get_predictions(text)
print("Output vector:", output_vector)
print("Prediction:", prediction)Output:
Output vector: [0.38528103 0.61471903]
Prediction: positiveThat’s pretty much 61% sure it’s a good sentiment and you can see that it gives interesting results and takes some time to deceive the model!
Hyperparameter tuning
Python text classification example: Before I came up with 90% accuracy, I had tried various hyperparameters, and here are some interesting ones:
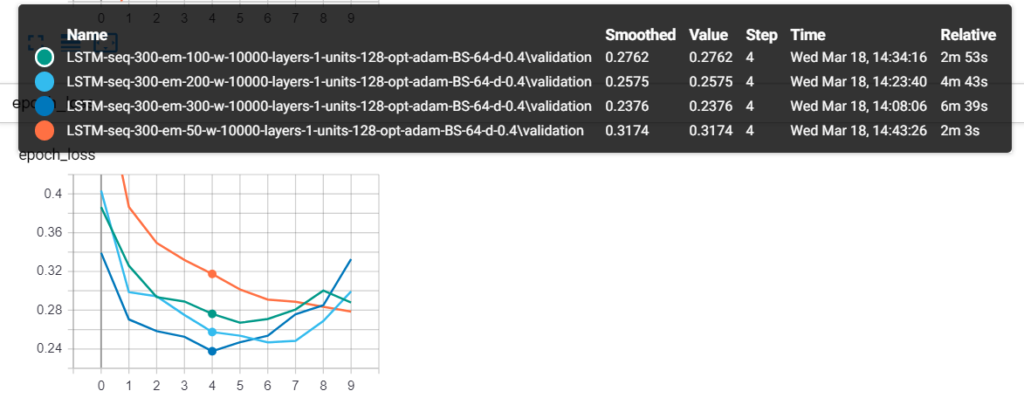
These are 4 models, each with a different embedding size, and as you can see, the model with 300 length vectors (300 length vectors per word) achieves the lowest validation loss value.
Here’s another one when I use sequence length as a variadic:

Models with a sequence length of 300 (green) tend to perform better.
Using tensorboard, you can see that after reaching epochs 4-5-6, the validation loss will try to increase again, which is clearly overfitting. That’s why I set epochs to 6. Try adjusting other parameters, such as dropout rates, to see if you can reduce them further.
Integrate custom datasets
How does Python classify text? Since this is a text classification tutorial, this is useful if you can use your own dataset without changing most of the code for this tutorial. In fact, all you need to change is load the data function, earlier we used the load_imdb_data() function, which returns a data dictionary that has:
X_train: A NumPy array whose shape (number of training samples, sequence length) contains all sequences for each data sample.X_test: Same as above, but used for test samples.y_train: These are the labels of the training set, which is a NumPy array of shapes (number of test samples, total number of classes), which in the case of sentiment analysis should look something like (15000, 2)y_test: Same as above, but used for test samples.tokenizer: This is a Tokenizer instance from the tensorflow.keras.preprocessing.text module that is used to mark objects in the corpus.label2int: Converts the label into a Python dictionary of its corresponding encoded integer, in the sentiment analysis example, we use 1 for positive and 0 for negative.int2label:Vice versa.
Python implements text classification using Tensorflow 2 and Keras – this is an example function that loads a 20 newsgroup dataset (approximately 18,000 newsgroup posts with 20 topics) using sklearn’s built-in function fetch_20newsgroups():
from sklearn.datasets import fetch_20newsgroups
def load_20_newsgroup_data(num_words, sequence_length, test_size=0.25, oov_token=None):
# load the 20 news groups dataset
# shuffling the data & removing each document's header, signature blocks and quotation blocks
dataset = fetch_20newsgroups(subset="all", shuffle=True, remove=("headers", "footers", "quotes"))
documents = dataset.data
labels = dataset.target
tokenizer = Tokenizer(num_words=num_words, oov_token=oov_token)
tokenizer.fit_on_texts(documents)
X = tokenizer.texts_to_sequences(documents)
X, y = np.array(X), np.array(labels)
# pad sequences with 0's
X = pad_sequences(X, maxlen=sequence_length)
# convert labels to one-hot encoded
y = to_categorical(y)
# split data to training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=1)
data = {}
data["X_train"] = X_train
data["X_test"]= X_test
data["y_train"] = y_train
data["y_test"] = y_test
data["tokenizer"] = tokenizer
data["int2label"] = { i: label for i, label in enumerate(dataset.target_names) }
data["label2int"] = { label: i for i, label in enumerate(dataset.target_names) }
return dataOk, good luck in implementing your own text classifier, and if you have any problems integrating the classifier, please leave your comment below and I’ll get in touch with you as soon as possible.
As I mentioned before, trying to experiment with all the hyperparameters provided, I try to write code that is as flexible as possible so that you can just change the parameters without doing anything else. If your parameters exceed mine, please share them with us in the comments below!