Data Mining Interview Questions and Answers Collection: Data mining is the process of extracting useful information from a data warehouse or batch of data. This article contains the most popular and common interview questions for data mining and their detailed answers. These will help you crack any interview for a data scientist job. Let’s get started.

What are the Common Data Mining Interview Questions and Answers?
1. What is Data Mining?
Data Mining Interview Questions Collection: Data mining refers to extracting or mining knowledge from large amounts of data. In other words, data mining is the science, art, and technology of discovering large amounts of complex data to discover useful patterns.
2. What are the different tasks of data mining?
Perform the following activities during data mining:
- classify
- clustering
- Association rule discovery
- Sequential pattern discovery
- regression
- Deviation detection
3. Discuss the life cycle of a data mining project?
Life Cycle of a Data Mining Project:
- Business Understanding: Understand the project objectives from a business perspective, data mining problem definition.
- Data comprehension: Collect the data initially and make sense of it.
- Data preparation: Build a final dataset from raw data.
- Modeling: Select and apply data modeling techniques.
- Evaluate: Evaluate the model and decide on further deployment.
- Deploy: Create reports to take action based on new insights.
4. What is the process of explaining KDD?
A collection of frequently asked questions about data mining? Data mining is seen as a synonym for another commonly used term, discovering knowledge from data, or KDD. To others, data mining is just an important step in the knowledge discovery process, where intelligent methods are applied to extract patterns in data.
Uncovering knowledge from data includes the following steps:
- Data cleansing (removal of noise or irrelevant data).
- Data integration (multiple data sources can be combined).
- Data selection (retrieving data from a database that is relevant to the analysis task).
- Data transformation (the transformation or merging of data into a form suitable for mining by performing a summary or aggregation function on a sample).
- Data mining (the important process of applying intelligent methods to extract patterns in data).
- Pattern assessment (to identify fascinating patterns that represent knowledge based on some interesting metrics).
- Knowledge presentation (where knowledge representation and visualization techniques are used to present mined knowledge to users).
5. What is Classification?
Classification is the process of finding a set of models (or functions) that describe and distinguish data classes or concepts, with the aim of being able to use the model to predict a class of objects whose class labels are unknown. Classification can be used to predict the category label of a data item. However, in many applications, one may prefer to calculate some missing or unavailable data values instead of class labels.
6. Interpreting evolution and bias analysis?
What are the Common Data Mining Interview Questions and Answers? Data evolution analysis describes and models patterns or trends in the behavior of objects that change over time. Although this may involve differentiating, correlating, classifying, characterizing, or clustering time-correlated data, the different characteristics of this type of analysis involve time series data analysis, periodic pattern matching, and similarity-based data analysis.
When analyzing time-related data, it is often necessary not only to model the overall evolutionary trend of the data, but also to identify data bias that occurs over time. Deviation is the difference between a measured value and a corresponding reference value, such as a previous value or a canonical value. A data mining system that performs a deviation analysis, after detecting a set of deviations, may do the following: describe the characteristics of the deviation, try to describe the reasons behind it, and suggest measures to bring the deviation value back to its expected value.
7. What is Forecasting?
Prediction can be thought of as building and using a model to evaluate the category of an unlabeled object, or to measure the value or range of values for a given object that may have. In this interpretation, classification and regression are the two main types of prediction problems, where classification is used to predict discrete or nominal values, while regression is used to predict continuous or ordinal values.
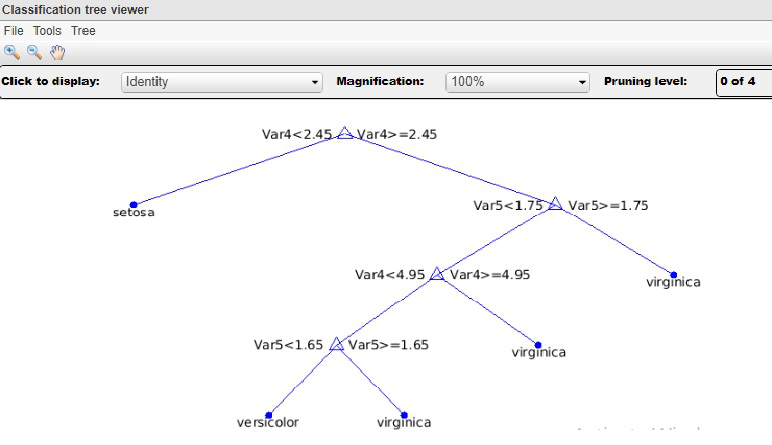
8. Explain the Decision Tree Classifier?
Data Mining Interview Questions and Answers Collection: A decision tree is a flowchart-like tree structure where each internal node (non-leaf node) represents a test for an attribute, each branch represents the result of the test, and each leaf node (or endpoint) holds a class label. The topmost node of the tree is the root node.
A decision tree is a classification scheme that generates a tree and a set of rules from a given dataset that represent different classes of models. The set of records that can be used to develop a classification method is typically divided into two disjoint subsets, the training set and the test set. The former is used to generate a classifier, and the latter is used to measure the accuracy of a classifier. The accuracy of the classifier is determined by the percentage of test examples that are correctly classified.
In a decision tree classifier, we divide the recorded attributes into two different types. Attributes that define the domain as numeric are called numeric attributes, and attributes that define the domain as non-numeric are called categorical attributes. There is a unique property called a class tag. The goal of classification is to build a concise model that can be used to predict the category of records with unknown category labels. Decision trees can simply be converted into classification rules.
9. What are the advantages of a decision tree classifier?
- Decision trees produce intelligible rules.
- They are able to work with numbers and categorical attributes.
- They are easy to understand.
- Once the decision tree model is established, the classification of test records is very fast.
- The decision tree is rich enough to represent any discrete value classifier.
- Decision trees can work with datasets that may have errors.
- Decision trees can handle processing datasets that may have missing values.
- They don’t require any prior assumptions. Decision trees are self-explanatory and easy to understand when compressed. That is, if the number of leaves in the decision tree is reasonable, it can be mastered by non-expert users. Also, since the decision tree can be converted into a set of rules, this representation is considered intelligible.
10. Explain Bayesian Classification in Data Mining?
A Bayesian classifier is a type of statistical classifier. They can predict class member probabilities, for example, the probability that a given sample belongs to a particular class. Bayesian classifications are created based on Bayes’ theorem. A simple Bayesian classifier is known as a naïve Bayesian classifier, and its performance is comparable to that of decision trees and neural network classifiers. Bayesian classifiers also exhibit high accuracy and speed when applied to large databases.
11. Why is fuzzy logic an important area of data mining?
The disadvantage of rule-based classification systems is that they involve precise values of continuous attributes. Fuzzy logic is useful for data mining systems that perform classification. It provides the benefit of working at a high level of abstraction. In general, the use of fuzzy logic in rule-based systems involves the following:
- The attribute value is changed to a fuzzy value.
- For a given new sample, more than one fuzzy rule may be applied. Each applicable rule votes for membership in the category. In general, the truth values for each projection category are summed.
- The sum obtained above is combined into a value returned by the system. This process can be done by weighting and multiplying the sum of the truth values of each category by the average truth of each category. The calculations involved can be more complex, depending on the difficulty of the fuzzy membership map.
12. What is a neural network?
A neural network is a set of connected input/output units, where each connection has a weight associated with it. During the knowledge phase, the network adjusts the weights to obtain the correct class label that predicts the input sample. Neural network learning is also known as connection learning because of the connections between units. Neural networks involve a long training time, making them more suitable for viable applications. They require a number of parameters that are often best determined empirically, such as network topology or “structure”. Neural networks have been criticized for their poor interpretability, as it is difficult for humans to understand the symbolism behind the weighting of learning. These characteristics make neural networks less suitable for data mining in the first place.
However, neural networks have the advantage of being highly tolerant of noisy data and their ability to classify untrained patterns. In addition, several algorithms have been newly developed for extracting rules from trained neural networks. These questions contribute to the usefulness of neural networks for classification in data mining. The most popular neural network algorithm is the backpropagation algorithm proposed in the 1980s
13. How does a backpropagation network work?
Backpropagation learns by iteratively processing a set of training examples, comparing the network’s estimate of each sample with an actually known class label. For each training sample, the weights are modified to minimize the mean square error between the network prediction and the actual class. These changes are made in the “backward” direction, i.e. from the output layer, through each hidden layer down to the first hidden layer (hence the term backpropagation). Although there is no guarantee, in general, the weights will eventually converge and the knowledge process stops.
14. Data Mining Interview Questions and Answers Collection: What is Genetic Algorithm?
Genetic algorithms are part of evolutionary computing, a rapidly evolving field of artificial intelligence. The genetic algorithm was inspired by Darwin’s theory of evolution. Here evolved the solution to the problem solved by the genetic algorithm. In genetic algorithms, a set of strings (called chromosomes or genotypes of genes) encode candidate solutions to optimization problems (called individuals, organisms, or phenotypes) to evolve toward better solutions. Traditionally, solutions have been represented as binary strings, consisting of 0s and 1s, and other encoding schemes can do the same.
15. What is classification precision?
The classification accuracy, or the accuracy of the classifier, is determined by the percentage of test dataset examples that are correctly classified. Classification accuracy of the classification tree = (1 – generalization error).
16. What Are Some Common Data Mining Interview Questions and Answers? Defining Clustering in Data Mining?
Clustering is the task of dividing a population or data point into groups so that data points in the same group are more similar to other data points in the same group and different from those in other groups. It is basically a collection of objects based on similarities and differences between them.
17. Data Mining Interview Questions Collection: Write a Difference Between Classification and Clustering? [IMP]
| parameter | classify | clustering |
|---|---|---|
| type | For supervised learning of needs | For unsupervised learning |
| essential | The process of classifying input instances based on the corresponding class labels | Group instances based on their similarity without the help of class tags |
| need | It has labels, so you need to train and test the dataset to validate the model you created | There is no need to train and test datasets |
| complex | More complex compared to clustering | Less complicated compared to classification |
| Example algorithm | Logistic regression, naïve Bayesian classifiers, support vector machines, etc. | k-means clustering algorithm, Fuzzy c-means clustering algorithm, Gaussian (EM) clustering algorithm, etc. |
18. What is supervised learning and unsupervised learning? 【TCS Interview Questions】
As the name suggests, supervised learning has a supervisor as the teacher. Basically, supervised learning is when we use well-labeled data to teach or train a machine. This means that some of the data has already been marked as the correct answer. After that, the machine is provided with a new set of examples (data) so that the supervised learning algorithm analyzes the training data (the set of training examples) and produces the correct results from the labeled data.
Unsupervised learning is the training of a machine with information that is neither classified nor labeled and allows the algorithm to act on that information without guidance. Here, the task of the machine is to group unclassified information based on similarities, patterns, and differences without any prior training on the data.
Unlike supervised learning, no teacher is provided, which means that no training will be given to the machine. As a result, machines are limited to finding hidden structures in unlabeled data on their own.
19. What are the application areas of named data mining?
- Financial data mining applications
- health care
- intellect
- telecommunications
- vitality
- retail
- E-commerce
- supermarket
- Criminal institutions
- Businesses benefit from data mining
20. What are the problems with data mining?
There are a few issues that need to be addressed by any serious data mining package
- Uncertainty handling
- Handle missing values
- Process noisy data
- Algorithmic efficiency
- Limit the knowledge you find to only usefulness
- Combine domain knowledge
- The size and complexity of the data
- Data selection
- Comprehensibility of discovered knowledge: The consistency between the data and the discovered knowledge.
21. What about the Data Mining Query Language?
A collection of frequently asked questions about data mining? DBQL or Data Mining Query Language proposed by Han, Fu, Wang, et al. The language is available for DBMiner data mining systems. DBQL queries are based on SQL (Structured Query Language). We can also use this language for databases and data warehouses. This query language supports both ad hoc and interactive data mining.
22. What is the difference between data mining and data warehousing?
Data mining: It is the process of finding patterns and correlations in large data sets to identify relationships between data. Data mining tools allow business organizations to predict customer behavior. Data mining tools are used to build risk models and detect fraud. Data mining is used for market analysis and management, fraud detection, enterprise analysis, and risk management.
It is a technique for aggregating structured data from one or more sources so that it can be compared and analyzed, rather than transacted.
Data warehouse: A data warehouse is designed to support the management decision-making process by providing a platform for data cleansing, data integration, and data consolidation. A data warehouse contains topic-oriented, integrated, time-varying and non-volatile data.
A data warehouse consolidates data from multiple sources while ensuring data quality, consistency, and accuracy. A data warehouse improves system performance by separating analytical processing from multinational databases. Data flows into the data warehouse from various databases. A data warehouse works by organizing data into schemas that describe the layout and types of data. The query tool analyzes the data table using schemas.
23. What is Data Eraser?
The term purge can be defined as erasing or deleting. In the context of data mining, data purging is the process of permanently removing unnecessary data from a database and cleaning the data to maintain its integrity.
24. What is Cube?
Data Mining Interview Questions and Answers Collection: Data cubes store data in aggregated versions, which helps analyze data faster. Data is stored in a way that allows for easy reporting. For example, using Data Cube Users might want to analyze the performance of their employees on a weekly, monthly basis. Here, the month and week can be considered as the dimensions of the cube.
25.What is the difference between OLAP and OLTP? [IMP]
| OLAP (On-Line Analytical Processing) | OLTP (Online Transaction Processing) |
|---|---|
| Consists of historical data from various databases. | Only the current data for the day-to-day operations of the application is included. |
| App-oriented day-to-day is topic-oriented. It is used for data mining, analysis, decision-making, etc. | It is application-oriented. For business tasks. |
| Data is used for planning, problem solving, and decision-making. | This data is used to perform basic operations on a day-to-day basis. |
| It shows a snapshot of the current business task. | It provides a multi-dimensional view of different business tasks. |
| Large amounts of foreign exchange data are usually stored in terabytes and petabytes | Since historical data is archived, the size of the data is comparatively smaller. For example, MB, GB |
| It is comparatively slow due to the large amount of data involved. Inquiries can take several hours. | Very fast because the query operates on 5% of the data. |
| In contrast to OLTP, it only requires backups from time to time. | The backup and recovery process is religiously maintained |
| This data is typically managed by the CEO, MD, GM. | This data is managed by clerks, managers. |
| There are only read operations, and very few write operations. | Read and write operations. |
26. Explain Association Algorithms in Data Mining?
Association analysis is the discovery of attribute value conditions that association rules often appear together in a given dataset. Correlation analysis is widely used in market basket or transaction data analysis. Association rule mining is an important and extremely active field in data mining research. An association-based classification method is called association classification and consists of two steps. In the main step, association instructions are generated using a modified version of the standard association rule mining algorithm called Apriori. The second step is to construct a classifier based on the discovered association rules.
27. Explain How to Use Data Mining Algorithms Included in SQL Server Data Mining?
SQL Server Data Mining provides the Data Mining add-on for Office 2007 that allows you to find patterns and relationships of information. This helps to improve the analysis. An add-in called the Excel Data Mining Client is used for initial preparation of information, creation of models, management, analysis, and results.
28. Explain overfitting?
The concept of overfitting is very important in data mining. It refers to a situation in which a classifier generated by an inductive algorithm perfectly matches the training data, but loses the ability to generalize to instances that were not presented during training. In other words, the classifier only remembers the training instance and not learns. In decision trees, overfitting often occurs when the number of nodes in the tree is too large relative to the amount of training data available. By increasing the number of nodes, the training error is usually reduced, and at some point the generalization error gets worse. When there is noise in the training data or when the number of training datasets is high, overfitting can cause difficulties when the error of a fully constructed tree is zero, while the true error may be greater.
Overfitting decision trees have a number of drawbacks:
- An overfitting model is incorrect.
- Overfitting decision trees require more space and more computational resources.
- They need to collect unnecessary features.
29. Define tree pruning?
When building a decision tree, many branches reflect anomalies in the training data due to noise or outliers. The tree pruning method solves the problem of overfitting the data. So tree pruning is a technique to eliminate the problem of overfitting. Such methods typically use statistical measures to remove the least reliable branches, often resulting in faster classification and improved ability of the tree to correctly classify independently test data. The pruning phase eliminates some of the lower branches and nodes to improve its performance. Treat pruned trees to improve comprehensibility.
30. What is Thorn?
The statistics grid is called STING; It is a grid-based multi-resolution clustering strategy. In a STING strategy, each item is contained in rectangular cells that maintain varying degrees of resolution, and the levels are organized in a hierarchical structure.
31 . Defining the Chameleon Method?
Chameleon is another hierarchical clustering technique that utilizes dynamic modeling. Chameleon is familiar with the shortcomings of the recovery CURE clustering technique. In this technique, two groups are combined if the interconnectivity between two clusters is greater than the interconnectivity between objects within the cluster/group.
32. Explain Questions About Classification and Forecasting?
Prepare data for classification and prediction:
- Data cleansing
- Correlation analysis
- Data Conversion
- Compare classification methods
- Forecast accuracy
- velocity
- robustness
- Scalability
- Explainability
33. Explain the use of data mining queries or why are data mining queries more helpful?
Data mining queries are primarily applied to models of new data to produce single or multiple different results. It also allows us to provide input values. If a particular schema is defined correctly, the query can effectively retrieve information. It takes the statistical memory of the training data and gets the specific designs and rules that address a common case of a pattern in the model. It helps in extracting regression formulas and other calculations. It also recovers insights about the individual cases used in the model. It incorporates information that is not used in the analysis, it keeps the model and performs tasks and cross-validations with the help of adding new data.
34. What is a machine learning-based data mining method?
This question is an advanced data mining interview question asked in an interview. Machine learning is primarily used in data mining because it covers automatically programming processing systems, and it relies on logical or binary tasks. Machine learning largely follows rules that allow us to manage more general types of information, merging cases, where the number of attributes can vary. Machine learning is one of the well-known programs used for data mining and artificial intelligence.
35. What is the K-means algorithm?
K-means Clustering Algorithm – It is the simplest unsupervised learning algorithm to solve clustering problems. The K-means algorithm divides n observations into k clusters, each of which belongs to the cluster, with the nearest mean as the prototype of the cluster.

Figure: K-Means Clustering property division
36. What Are Some Common Data Mining Interview Questions and Answers? What is accuracy and recall? [IMP]
Precision is the most commonly used error measure in the n-classification mechanism. It ranges from 0 to 1, where 1 represents 100%.
The recall can be defined as the number of actual positives in our model with a category label of positive (true positive)”. The recall rate and true positive rate are exactly the same. Here’s the formula for it:
Recall = (True Positive) / (True Positive + False Negative)

37. What is the ideal situation in which T-Test or Z-Test can be used?
As standard practice, the t-test is used when the sample size is less than 30 attributes, and the z-test is considered when the sample size is more than 30.
38. What is the simple difference between normalized and non-standardized coefficients?
In the case of normalization coefficients, their interpretation depends on their standard deviation values. Non-normalized coefficients are estimated based on the actual values present in the dataset.
39. Data Mining Interview Questions Collection: How to Detect Outliers?
Many methods can be used to distinguish outlier anomalies, but the two most commonly used techniques are as follows:
- Standard Deviation Strategy: Here, if the value is less or more than three standard deviations above the mean, the value is considered an outlier.
- Boxplot technique: Here, if a value is less or greater than 1.5 times the interquartile range (IQR), it is considered an outlier
40. Why is KNN preferred when identifying missing numbers in your data?
K-nearest neighbor (KNN) is preferred here because KNN can easily estimate the value to be determined based on the value closest to it.
The k-nearest neighbor (K-NN) classifier is treated as an example-based classifier, which means that the training document is used for comparison, rather than a precise class description like the class profiles used by other classifiers. So, there is no real training part. Once a new document has to be classified, k of the most similar documents (neighbors) are found, and if a large enough proportion of them are assigned to an exact class, the new document is also assigned to the current class, otherwise it will not. In addition, using traditional classification strategies can speed up the search for your nearest neighbor.
41. A collection of frequently asked questions about data mining? Explain the Prepruning and Post pruning methods in taxonomy?
Pre-pruning: In the pre-pruning approach, a tree is “pruned” by stopping the build early (e.g., by deciding not to further split or split a subset of the training samples at a given node). When stopped, the node becomes a leaf. Leaves may contain the most frequent categories in a subset of samples, or the probability distribution of those samples. When building a tree, metrics such as statistical significance, information gain, and so on can be used to evaluate the merits of splitting. If partitioning a sample at a node would result in splitting below a pre-specified threshold, stop further partitioning of a given subset. However, there are problems in choosing the right threshold. A high threshold can lead to an oversimplified tree, while a low threshold can lead to a very small simplification.
Post-pruning: The post-pruning method removes branches from a “fully grown” tree. Trim tree nodes by deleting their branches. The cost complexity pruning algorithm is an example of a post-pruning method. The pruned node becomes a leaf and is marked by the most frequent class in its former branch. For each non-leaf node in the tree, the algorithm calculates the expected error rate that would occur if the subtree at that node were pruned. Next, the predictable error rate that occurs if the node is not pruned is calculated using the error rate for each branch, which is aggregated by weighting the proportion of observations for each branch. If pruning a node results in a greater possible error rate, the subtree is retained. Otherwise, it is trimmed. After generating a set of progressively pruned trees, an independent test set is used to estimate the accuracy of each tree. Decision trees that minimize the expected error rate are preferred.
42. How do I deal with suspicious or missing data in a dataset when performing an analysis?
If there are any inconsistencies or uncertainties in the dataset, users can continue to use any of the accompanying techniques: Create validation reports with insights about the data in the conversation Upgrade something very similar to an experienced data analyst to review it and accept the call, replace invalid information with a comparison of large and up-to-date data information, use multiple methods to find missing values together and use approximate estimates if necessary.
43. What is the simple difference between Principal Component Analysis (PCA) and Factor Analysis (FA)?
Data Mining Interview Questions and Answers Collection: Among the many differences, the significant difference between PCA and FA is that factor analysis is used to determine and process the variance between variables, while PCA focuses on explaining the covariance between the current segment or variables.
44 . What is the difference between data mining and data analysis?
| data mining | data analysis |
|---|---|
| Used to perceive the design in stored data. | Used to arrange and combine raw information in an important way. |
| Mining is carried out in a clean and well-documented condition. | Information analysis includes data cleansing. As a result, the information cannot be provided in a well-documented format. |
| The results extracted from data mining are difficult to interpret. | The results extracted from the analysis of information are not difficult to interpret. |
45. What is the difference between data mining and data profiling?
- Data mining: Data mining refers to the analysis of information about the discovery of relationships that were not previously discovered. The main focus is on the identification of strange records, conditions, and cluster checks.
- Data analysis: Data analysis can be described as the process of analyzing individual attributes of data. It mainly focuses on providing important data about the attributes of the information, such as the type of information, repeatability, etc.
46. What are the important steps in the data validation process?
As the name suggests, data validation is the process of approving information. There are two main ways in which this progress is carried out. These are data filtering and data validation.
- Data filtering: In this session, different types of calculations are used to sift through the entire information to find any inaccurate quality.
- Data validation: Each hypothesis is evaluated on a different use case, and then a final conclusion is drawn about whether the value must be remembered for the information.
47. What is the difference between monastic and binary analysis, and multivariate analysis?
The main differences between univariate, bivariate, and multivariate surveys are as follows:
- Univariate: A statistical program that can be separated based on the factor checks required for a given time instance.
- Bivariate: This type of analysis is used to find the difference between two variables at a time.
- Multivariate: The analysis of multiple variables is called multivariate. This analysis is used to understand the impact of factors on the response.
48. What is the difference between variance and covariance?
Variance and covariance are two mathematical terms that often appear in the field of statistics. Variance fundamentally deals with the way in which numbers are separated from the mean. Covariance refers to how two random/irregular factors will change together. This is mainly used to calculate the correlation between variables.
49. What are the different types of hypothesis testing?
The various hypothesis tests are as follows:
- T-test: When the standard deviation is unknown and the sample size is almost small, the T-test is used.
- Chi-square tests for independence: These tests are used to find the significance of associations between all categorical variables in a population sample.
- Analysis of Variance (ANOVA): This type of hypothesis testing is used to examine the comparison of methods in different clusters. This test is used in contrast to the T-test, but is used for multiple groups.
Welch’s T-test: This test is used to find tests where the mean is equal between two test sample tests.
50. Why use a data warehouse and how do I extract data for analysis?
Data warehousing is a key technology for building business intelligence. A data warehouse is a collection of data taken from an enterprise’s operational or transactional systems, transformed to remove any inconsistencies in identity codes and definitions, and then arranged to support rapid reporting and analysis.
Here are some of the benefits of a data warehouse:
- It operates the database independently.
- Integrate data from heterogeneous systems.
- Store massive amounts of data that are more historically significant than current data.
- The data does not need to be highly accurate.
Bonus Interview Questions and Answers
1. What is Visualization?
Visualization is used to describe data and gain an intuition about the data being observed. It helps analysts choose the display format, viewer perspective, and data representation mode.
2. Provide some data mining tools?
- Database miner
- Geological miner
- Multimedia miner
- Blog Miner
3. What are the most significant advantages of data mining?
There are many advantages to data mining. Some of them are listed below:
- Data mining is used to polish raw data, allowing us to explore, identify, and understand patterns hidden in the data.
- It can automatically look up predictions in large databases, helping to identify previously hidden patterns in a timely manner.
- It helps make faster and better decisions, which in turn helps businesses take the necessary actions to increase revenue and reduce operating costs.
- It is also used to help with data screening and validation to understand where the data is coming from.
- Using data mining techniques, experts can manage applications in various fields such as market analysis, production control, sports, fraud detection, astrology, and more.
- Shopping websites use data mining to define shopping patterns and design or select products for better revenue.
- Data mining also helps in data optimization.
- Data mining can also be used to determine hidden profitability.
4. What are “Training Sets” and “Test Sets”?
In various areas of information science, such as machine learning, a set of data is used to discover potential predictive relationships, known as a “training set.” The training set is an example given to the learner, while the test set is used to test the accuracy of the hypotheses generated by the learner, and it is the set of examples that the learner blocks. The training set is different from the test set.
5. Explain what is the function of “unsupervised learning”?
- Find data clusters
- Find low-dimensional representations of data
- Look for interesting directions in the data
- Interesting coordinates and correlation
- Look for new observations/database cleanups
6. What are the areas where pattern recognition is used?
Pattern recognition can be used
- Computer vision
- Speech recognition
- data mining
- Statistics
- Informal searches
- Bioinformatics
7. What is Ensemble Learning?
To solve a specific computational program, strategically generate and combine multiple models, such as classifiers or experts, to solve a specific computational program, Multiple. This process is known as ensemble learning. Ensemble learning is used when we build component classifiers that are more accurate and independent of each other. This learning is used to improve classification, data prediction, and function approximation.
8. What are the general principles of the ensemble approach and what are the bagging and boosting in the ensemble approach?
The general principle of the ensemble approach is to combine the predictions of multiple models built with a given learning algorithm in order to improve the robustness of a single model. Bagging is a method used in an ensemble to improve an unstable estimation or classification scheme. At the same time, the boosting method is used to reduce the bias of the combined model. Both boosting and bagging can reduce errors by reducing the variance term.
9. What are the components of a relationship assessment technique?
An important part of relationship assessment techniques is:
- Data acquisition
- Ground live collection
- Cross-validation techniques
- The type of query
- Scoring metrics
- Significance test
10. What Are The Different Methods Of Sequentially Supervised Learning?
The different ways to solve the problem of sequential supervised learning are:
- Sliding window method
- Cycle through the sliding window
- Hidden Markov model
- Maximum entropy Markow model
- Conditional random field
- Graph converter network
11. What is a random forest?
Random forests are a machine learning method that helps you perform all types of regression and classification tasks. It is also used to handle missing values and outliers.
12. What is reinforcement learning?
Data Mining Interview Questions Collection: Reinforcement learning is a learning mechanism about how to map situations to actions. The end result should help you increase your binary reward signals. In this approach, the learner is not told which action to take, but must discover which action provides the greatest reward. The method is based on a reward/punishment mechanism.
13. A collection of frequently asked questions about data mining? Is it possible to capture correlations between continuous and categorical variables?
Yes, we can use the analysis of the covariance technique to capture the association between continuous and categorical variables.
14. What is Visualization?
Visualization is used to describe information and gain knowledge about the information being observed. It helps experts choose the format design, viewer’s perspective, and information representation mode.
15. List Some Of The Best Tools You Can Use For Data Analysis.
What are the Common Data Mining Interview Questions and Answers? The most commonly used data analysis tools are:
- Google Search Operators
- KNIME
- Tableau
- Solver
- RapidMiner
- Io
- NodeXL
16. Describe the structure of an artificial neural network?
Data Mining Interview Questions and Answers Collection: Artificial Neural Networks (ANNs), also known simply as “neural networks” (NNs), can be process models supported by biological neural networks. Its structure consists of a collection of interconnected artificial neurons. An artificial neural network is an adjective system that changes the structural support information that flows through the artificial network in the learning part. Artificial neural networks rely on the principle of learning by example. However, there are two classical types of neural networks, perceptrons and multilayer perceptrons. Here, we’ll target perceptron algorithm rules.
17. Do you think 50 small decision trees are better than one big? Why?
Yes, 50 small decision trees are better than large decision trees because 50 trees make the model more robust (less prone to overfitting) and easier to interpret.