In this Python sentiment analysis tutorial, we help simplify sentiment analysis using Python. You’ll learn how to build your own sentiment analysis classifier using Python and learn the basics of NLP (Natural Language Processing).
The promise of machine learning has shown many amazing results in various fields. Natural language processing is no exception, and it is one of the areas where machine learning is able to demonstrate that artificial general intelligence (not completely, but at least partially) has achieved some brilliant results on truly complex tasks.
Now, NLP (Natural Language Processing) is not a new field, and neither is machine learning. But the convergence of these two areas is very modern and only vows to progress. This is one of those hybrid apps that everyone (with a cheap smartphone) comes across on a daily basis. For example, include “keyboard word suggestions” in your account, or smart autocomplete; These are all byproducts of the convergence of NLP and machine learning, and naturally, these have become an integral part of our lives.
How does Python do sentiment analysis? Sentiment analysis is an important topic in the field of NLP. It is easily one of the hottest topics in the field because of its relevance and the number of business questions it is solving and being able to answer. In this tutorial, you’ll introduce this not-so-simple topic in a simple way. You’re going to break down all the little math behind it, and you’re going to study it. By the end of this tutorial, you’ll also have built a simple sentiment classifier. Specifically, you’ll cover:
- Understand sentiment analysis from a practitioner’s perspective
- Develop a problem statement for sentiment analysis
- Naive Bayesian classification for sentiment analysis
- Python sentiment analysis implementation
- Python Case Study
- How sentiment analysis affects multiple areas of business
- Read further on the topic
Let’s get started.

Source: Medium
What is Sentiment Analysis – Practitioner’s Perspective:
Essentially, sentiment analysis or sentiment classification falls under the broad category of a text classification task, where a list of phrases or phrases is provided, and your classifier should judge whether the sentiment behind it is positive, negative, or neutral. Sometimes, not taking a third attribute to keep it is a binary classification problem. In recent missions, emotions such as “a little positive” and “a little negative” were also taken into account. Now let’s understand with an example.
Python Sentiment Analysis Example – Consider the following phrases:
- “Titanic is a great movie.”
- “Titanic is not a good movie.”
- “Titanic is a movie.”
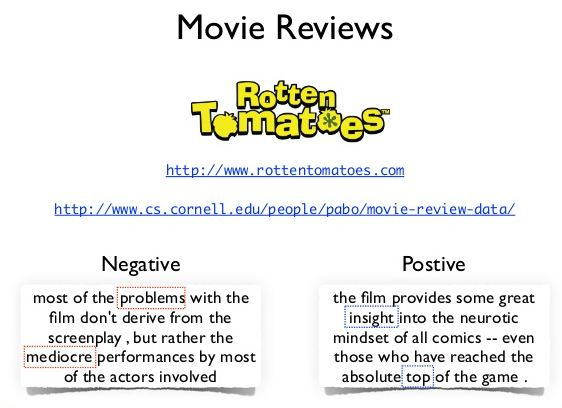
These phrases correspond to short movie reviews, and each phrase conveys a different emotion. For example, the first phrase indicates positive emotions towards the movie Titanic, while the second phrase thinks that the movie is not very good (negative emotions). Take a closer look at the third. There are no such words in the phrase that can tell you anything about the emotion it conveys. Therefore, this is an example of neutral emotions.
Now, from a rigorous machine learning perspective, this task is nothing more than a supervised learning task. You’ll provide the machine learning model with a bunch of phrases (labeled with their respective sentiments), and you’ll test the model on unlabeled phrases.
Just introducing sentiment analysis should be fine, but you need more to be able to build sentiment classification models. Let’s move on.
Source: SlideShare
Develop a Problem Statement for Sentiment Analysis:
Python Sentiment Analysis Implementation: Before understanding the problem statement for sentiment classification tasks, you need to have a clear understanding of general text classification problems. Let’s formally define the problem of a generic text classification task.
- Input:
- File d
- A fixed set of classes C = {c 1 ,c 2 ,..,c n }
- Output: Categories C∈∈ C of the prediction
The document terminology here is subjective because in the field of text classification. A document refers to a tweet, phrase, part of a news article, an entire news article, an entire article, a product manual, a story, etc. The reason behind this term is the word, which is an atomic entity, which in this case is small. Therefore, in order to denote a large number of word sequences, this term document is generally used. A tweet means a shorter document, while an article means a larger document.
So, a training set of n tagged documents would look like this:(d 1 ,c 1 ), (d 2 ,c 2 ),…,(d n ,c n )The final output is a learning classifier.
You did very well! But one of the questions you have to ask at this point is where are the characteristics of the document? Real problem! You’ll get to that later.
Now, let’s move on to asking questions and slowly build the intuition behind sentiment categorization.
How does Python do sentiment analysis? A key point you need to keep in mind when doing sentiment analysis is that not all words in a phrase convey the sentiment of that phrase. Words like “I”, “Are”, “Am”, etc., do not convey any type of emotion, and as such, they are not relevant in the context of sentiment classification. Consider the feature selection problem here. In feature selection, you try to find the most relevant features that are most relevant to the class label. The same idea applies here as well. As a result, only a few words in a phrase are involved, and identifying them and extracting them from the phrase proves to be a challenging task. But don’t worry, you’ll do it.
Consider the following movie reviews to better understand this:
“I love this movie! It’s sweet, but with a touch of irony. The dialogue is great and the adventure scenes are interesting. It manages to be romantic and whimsical while mocking the conventions of the fairy tale genre. I would recommend it to anyone about now. I’ve seen it several times and I’m always happy to see it again…… ”
Yes, this is undoubtedly a review with positive emotions towards a particular movie. But what are those specific words that define this positivity?
Take a second look at the comments.
“I love this movie! It’s sweet, but with a touch of irony. The dialogue is great and the adventure scenes are interesting. It manages to be romantic and whimsical while mocking the conventions of the fairy tale genre. I would recommend it to anyone about now. I’ve seen it several times and I’m always happy to see it again…… ”
You should have a clear picture by now. The bold words in the above passage are the most important words, and they constitute the positive nature of the emotion conveyed by the text.
What to do with these words? The next step that seems natural is to create a representation similar to:
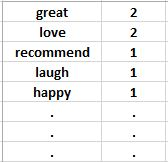
So what does the above representation do? You’ve guessed it by now. Each line contains a word and how often it appears in the document (from now on we will call it a document). You also wonder that love only comes out once, but why does it occur at a frequency of 2? Well, that’s part of the whole review. Think about it, the representation is for the entire review.
When formulating the problem statement for the sentiment classification task, you understand the “bag of words” representation, and the above representation is nothing more than a representation. This is probably the most basic concept in NLP and the first step in solving any text classification problem. So, make sure you understand it.Bag-of-words
The representation of a bag-of-words document contains not only specific words, but also all the unique words in the document and how often they occur. The bag is math here, so according to the definition of a set, the bag does not contain any repetitive words.set
But for this app, you are only interested in the bold words mentioned earlier, so the bag of words of this document will only contain those words.
Documentation is not written in a chaotic manner. Are they? The order of words in a document is crucial. But in the context of sentiment classification, this sequence is not very important. The more important or important part here is the presence of these words.
The words you find in the bag of words will now build the feature set of the document. So, let’s say you’re a collection of many movie reviews (docs), and you’ve created bag-of-word representations for each review and kept their labels (i.e., in this case, sentiment – +ve or -ve). Your training set should look like this:
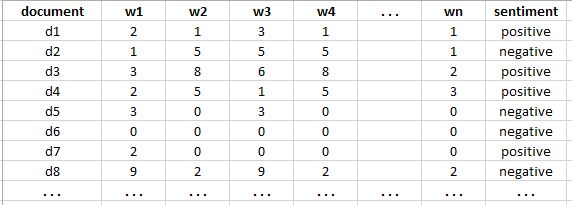
This representation is also known as a corpus.
This training set should be easy to explain –
All rows are independent feature vectors that contain information about a particular document (movie review), a particular word, and its mood. Note that label sentiment is often expressed as (+, -) or (+ve, -ve). In addition, the traits w1, w2, w3, 34, …, wn are generated from a bag of words, and it is not necessary for all documents to contain each of these features/words.
You pass these feature vectors to the classifier. So, let’s look at the naïve Bayes classification model for sentiment classification.
Python Sentiment Analysis Tutorial: Naive Bayesian Classification for Sentiment Analysis
Naive Bayesian classification is nothing more than the application of Bayesian rules to form categorical probabilities. In this section, you’ll learn the Naive Bayes classifier from the context of sentiment classification. It is highly recommended that you learn a little about the naive Bayesian classification and the Bayesian rule. The related resources are as follows:
- Starting Bayesian in R (Practice)
- 6 simple steps to learn the Naive Bayes algorithm
But why are there naïve Bayesian k-NNs, decision trees, and so on in the world? You’ll get to that later.
How does Python do sentiment analysis? Let’s start by constructing the concept of generic terms in naïve Bayesian classifiers in the context of sentiment classification. You’ll start by looking at Bayesian rules:
- For document D and class C:
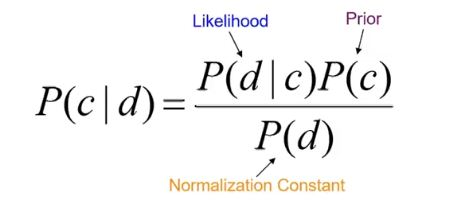
Source: Sentiment analysis
In this case, the class contains two emotions. Positive and negative.
Let’s explore each of the terms in the above diagram in detail in this context.
- The probability that the RHS term P(c|d) is read as category c for a given document d. The term is also known as the posterior.
- P(d|c) should be similar.
Now, what are these transcendental and likelihoods? In addition, the term P(d) (probability of documentation); Does this sound ridiculous? Gems of the problem! Let’s find out now!
- The term shown as a priori is your original belief that the original label of the document is positive or negative (in terms of sentiment).
- The term likelihood is the probability of document d given category c.
- Now the term posteriori is considered as an updated rule or an updated belief obtained by multiplying a priori and likelihood.
- But what is the normalization constant P(d)? This term is divided by the result produced by multiplication to ensure that the result can be presented in the probability distribution.
Not the best details until now! But keep going. You will find more information. But keep in mind that you’re still building your intuition to correlate Bayesian rules in the context of sentiment classification.
Python Sentiment Analysis Implementation: Let’s look in more detail about what exactly Bayesian rules are trying to do. The following diagram illustrates a more detailed step of the Bayesian rule:

Source: Sentiment analysis
There are a lot of unknown terms here. Let’s take our time.
Let’s start with the RHS term c MAP starts。 Here it denotes the main goal of Bayesian rules, which is to find out the maximum posterior probability/estimate of a certain document belonging to a particular category. MAP is an abbreviation for the Greek term.Max A Posteriori
What is? You could have used it!argmaxmax
- Well, it means index. Suppose P(+|d) > P(-|d) where + and – represent positive and negative emotions, respectively. These terms P(+|d), P(-|d) return the probability of a numeric quantity. However, you’re not interested in probability, you’re interested in finding a class with a larger P(+|d) and returning it. For P(+|d) > P(-|d), a + is returned.
argmaxargmaxargmax
Yes, you can remove the denominator P(d). It all depends on the implementation.
But how do I know about phosphorus ( d| c) phosphorus (d|C) and phosphorus (tri) phosphorus (C)? That’s where it comes in handy. But how?bag of words
Read on!
You already know how to convert a given document into a bag-of-word representation. What’s more, you can use this feature to represent a document as a set of features. So now, basically the term c MAPCan be written as (ignoring the denominator P(d)):
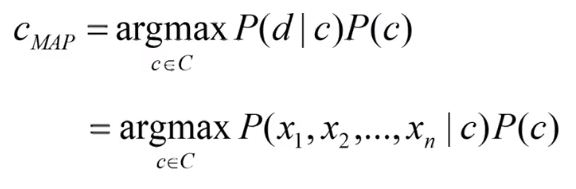
Source: Sentiment analysis
Python Sentiment Analysis Example: But, how do you really calculate probability? Let’s start with phosphorus (c) and phosphorus (C) first.
P(c) focuses primarily on the question: “How often does this class appear?” Let’s say your document dataset contains 60% positive sentiment and 40% negative sentiment. So, phosphorus(+) = 0.6phosphorus(+)=0.6 and phosphorus(-) = 0.4phosphorus(-)=0.4.
Now, how do you interpret the term: P(x1, x2,…,xn | c)?
Think of it this way – what is the probability of these words (features) appearing given category c. For example, let’s say you have 1000 documents and only two words in the corpus – “good” and “awesome”. Now, out of those 1000 documents, 500 are marked as positive and the remaining 500 are marked as negative. In addition, you find that out of 500 positively marked documents, 200 documents contain both “good” and “great” (note that P(x1,x2) means P(x1 and x2)). So, probability P(good,awesome | +) = 200 / 1000 = 1/5.
The important point you want to make here is that if your vocabulary is XX then you can formulateX nLikelihood (e.g., P(good, awesome | +)) probability, provided your document contains n words.
Keep in mind that you have to calculate the likelihood probability for both classes here. So, in the case where you have a total of 2000 words and each document contains an average of 20 words, the total number of combinations will be (2000) 20。 This number is outrageously large! What if the corpus size is in the millions (which does happen in real life)?
This is called a Bayesian classifier. But it just doesn’t work because there are too many calculations. Now, you’ll look at some of the assumptions that make a Bayesian classifier a naïve Bayesian classifier.
The hypothesis you are going to study is called the Naive Bayes independent hypothesis. They are as follows: P(x1, x2,…,xn | c)-bag-of-word assumption: The assumption is that the location does not matter. Suppose a particular word appears in the 10th and 20th positions, but with this assumption, it means that you only care about how often the word appears, i.e., 2. The numbers 10 and 12 don’t matter here.
–Conditional Independence Hypothesis: This is the key assumption that makes the Bayesian classifier naïve Bayes. It states that “assuming feature probability P(x i |c j )”。 Take a closer look at the statement. This means that P(x 1 |c j )、P(x 2 |c j ) and so on. (This does not mean that P(x.) 1), P(x 2 ) and so on) Now, the term P(x1, x2,…,xn | c) can be expressed as follows: Source: Sentiment Analysis
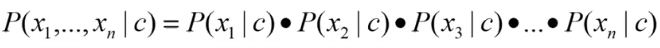
So, naturally,X nThe combination is reduced to Xn exponentially (if your vocabulary is XX and your document contains n words). Mathematically defined, a Bayesian classifier is simplified to a naïve Bayesian classifier as follows:
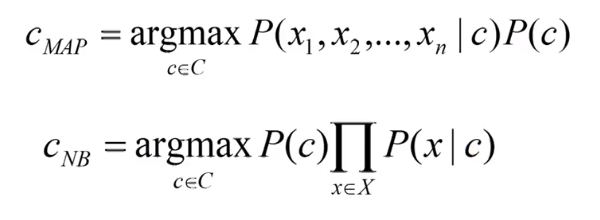
Source: Sentiment analysis
Naive Bayes has two advantages:
- Reduce the number of parameters.
- Linear time complexity is the opposite of exponential time complexity.
When the naïve Bayesian classification mechanism is applied to a text classification problem, it is referred to as “multinomial naïve Bayesian” classification.
Now, it’s easy for you to understand the mechanics of naïve Bayes classifiers, especially for sentiment classification problems. Now, it’s time to implement a sentiment classifier.
You’ll do it with Python! Let’s start with the case study.
Python Sentiment Analysis Tutorial: A Simple Python Sentiment Classifier:
For this case study, you’ll use the offline film review corpus presented in the NLTK book, which can be downloaded here. Provide a version of the dataset. The dataset classifies each review as positive or negative. You need to download it as follows:nltk
python -m nltk.downloader all
It is not recommended to run it from a Jupyter notebook. Try running it from a command prompt if you’re using Windows. This will take some time. So, be patient.
How does Python do sentiment analysis? You’ll implement Naive Bayes, or use multiple Naive Bayes classifiers that represent the Natural Language Toolkit. It’s a library dedicated to NLP and NLU-related tasks, and the documentation is excellent. It covers many techniques and provides free datasets as well as for experimentation.NLTK
This is the official website of the NLTK. Be sure to check it out as it has some well-written NLP tutorials that cover different NLP concepts.
Python Sentiment Analysis Example: Once you’ve downloaded all the data, you’ll start by importing the movie review dataset. Then, you’ll build a list of documents labeled with the appropriate categories.from nltk.corpus import movie_reviews
# Load and prepare the dataset
import nltk
from nltk.corpus import movie_reviews
import random
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
random.shuffle(documents)
Next, you’ll define a feature extractor for your document, so the classifier will know which aspects of the data it should also pay attention to. In this case, you can define a feature for each word that indicates whether the word is included in the document. To limit the number of features that the classifier needs to process, you first build a list of 2,000 of the most common words. corpus” source. You can then define a feature extractor that checks for the presence of each of these words in a given document.
# Define the feature extractor
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features
“The reason you count the set of all the words in the document instead of just checking if the word in the document exists is that it is much faster to check if the word appears in the set than to check if it appears in the list” – source.document_words = set(document)
Python Sentiment Analysis Implementation: You have defined a feature extractor. Now, you can use it to train a naive Bayes classifier to predict the sentiment of a new movie review. To check the performance of a classifier, you’ll calculate its accuracy on the test set. NLTK provides the ability to see which features the classifier finds are the most informative.show_most_informative_features()
# Train Naive Bayes classifier
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
# Test the classifier
print(nltk.classify.accuracy(classifier, test_set))
0.71
Wow! The classifier is able to achieve an accuracy rate of 71% without even adjusting any parameters or fine-tuning. It was great to go for the first time!
# Show the most important features as interpreted by Naive Bayes
classifier.show_most_informative_features(5)
Most Informative Features
contains(winslet) = True pos : neg = 8.4 : 1.0
contains(illogical) = True neg : pos = 7.6 : 1.0
contains(captures) = True pos : neg = 7.0 : 1.0
contains(turkey) = True neg : pos = 6.5 : 1.0
contains(doubts) = True pos : neg = 5.8 : 1.0
“In the dataset, comments mentioning ‘illogical’ were almost 8 times more likely to be negative than positive, while comments mentioning ‘captured’ were about 6 times more likely to be positive” – source.
Now the question – why naïve Bayes?
- You chose to study Naive Bayes because of the way it was designed and developed. Text data has some practical and complex features that are best mapped to naïve Bayes if you don’t consider neural networks. In addition, it is easy to explain and does not create the concept of a black box model.
Naive Bayes also have certain drawbacks:
The main limitation of Naive Bayes is the assumption of independent predictors. In real life, it’s almost impossible to get a completely independent set of predictors.
Why is sentiment analysis so important?
Sentiment analysis solves a number of real business problems:
- It helps predict the customer behavior of a particular product.
- It can help test the suitability of the product.
- Automate the task of reporting on customer preferences.
- By analyzing the sentiment behind movie reviews from multiple platforms, it can easily automate the process of determining how well a movie is performing.
- And many more!
Summary of the Python Sentiment Analysis tutorial
Congratulations! You’ve made it to the end. NLP is a very broad and interesting topic that solves some challenging problems. Specifically, the intersection of NLP and deep learning has led to some great products. It has revolutionized the way chatbots interact. The list is never-ending.
How does Python do sentiment analysis? This tutorial will hopefully give you a head start in one of the main subareas of NLP, namely sentiment analysis. You covered one of the most fundamental topics of NLP – bags of words, and then delved into naive Bayes classifiers in detail. You also checked its shortcomings. You’re using one of the most popular Python libraries for NLP and NLU tasks. You implemented a simple naïve Bayesian classifier using the provided film corpus. Give yourself a round of applause. You deserve it!nltknltk
If you want to start off this humble start and learn more about some amazing resources, here are some links:
- Research more about NLP and its different tools/techniques
- General study of textual data
- Study recurrent neural networks
- Learn about some amazing applications of NLP through deep learning
The following references were used to create this tutorial:
- Textual classification and naïve Bayes
- Use deep learning to predict emotions from movie reviews
- NLTK Books
- Fundamentals of Natural Language Processing